AWS DynamoDB is a NoSQL database service available in AWS Cloud.
DynamoDB provides many benefits starting from a flexible pricing model, stateless connection, and a consistent response time irrespective of the database size.
Due to this reason, DynamoDB is widely used as a database with serverless compute services like AWS Lambda and in microservice architectures.
In this tutorial, we will look at using the DynamoDB database in microservice applications built with Spring Boot along with code examples.
Check Out the Book!

This article gives only a first impression of what you can do with AWS.
If you want to go deeper and learn how to deploy a Spring Boot application to the AWS cloud and how to connect it to cloud services like RDS, Cognito, and SQS, make sure to check out the book Stratospheric - From Zero to Production with Spring Boot and AWS!
Example Code
This article is accompanied by a working code example on GitHub.AWS DynamoDB Concepts
Amazon DynamoDB is a key-value database. A key-value database stores data as a collection of key-value pairs. Both the keys and the values can be simple or complex objects.
There is plenty to know about DynamoDB for building a good understanding for which we should refer to the official documentation.
Here we will only skim through the main concepts that are essential for designing our applications.
Tables, Items and Attributes
Like in many databases, a table is the fundamental concept in DynamoDB where we store our data. DynamoDB tables are schemaless. Other than the primary key, we do not need to define any additional attributes when creating a table.
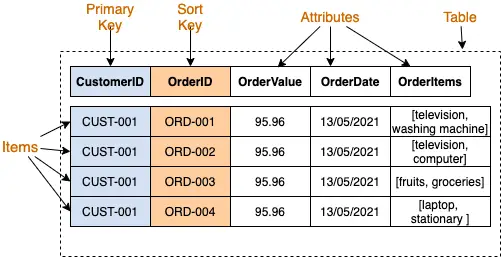
This diagram shows the organization of order records placed by a customer in a Order table. Each order is uniquely identified by a combination of customerID and orderID.
A table contains one or more items. An item is composed of attributes, which are different elements of data for a particular item. They are similar to columns in a relational database.
Each item has its own attributes. Most of the attributes are scalar like strings and numbers while some are of nested types like lists, maps, or sets. In our example, each order item has OrderValue, OrderDate as scalar attributes and products list as a nested type attribute.
Uniquely Identifying Items in a Table with Primary Key
The primary key is used to uniquely identify each item in an Amazon DynamoDB table. A primary key is of two types:
-
Simple Primary Key: This is composed of one attribute called the Partition Key. If we wanted to store a customer record, then we could have used
customerIDoremailas a partition key to uniquely identify the customer in the DynamoDB table. -
Composite Primary Key: This is composed of two attributes - a partition key and a sort keys. In our example above, each order is uniquely identified by a composite primary key with
customerIDas the partition key andorderIDas the sort key.
Data Distribution Across Partitions
A partition is a unit of storage for a table where the data is stored by DynamoDB.
When we write an item to the table, DynamoDB uses the value of the partition key as input to an internal hash function. The output of the hash function determines the partition in which the item will be stored.
When we read an item from the table, we must specify the partition key value for the item. DynamoDB uses this value as input to its hash function, to locate the partition in which the item can be found.
Querying with Secondary Indexes
We can use a secondary index to query the data in the table using an alternate key, in addition to queries against the primary key. Secondary Indexes are of two types:
- Global Secondary Index (GSI): An index with a partition key and sort key that are different from the partition key and sort key of the table.
- Local Secondary Index (LSI): An index that has the same partition key as the table, but a different sort key.
Writing Applications with DynamoDB
DynamoDB is a web service, and interactions with it are stateless. So we can interact with DynamoDB via REST API calls over HTTP(S). Unlike connection protocols like JDBC, applications do not need to maintain a persistent network connections.
We usually do not work with the DynamoDB APIs directly. AWS provides an SDK in different programming languages which we integrate with our applications for performing database operations.
We will describe two ways for accessing DynamoDB from Spring applications:
- Using DynamoDB module of Spring Data
- Using Enhanced Client for DynamoDB which is part of AWS SDK 2.0.
Both these methods roughly follow the similar steps as in any Object Relational Mapping (ORM) frameworks:
-
We define a data class for our domain objects like customer, product, order, etc. and then define the mapping of this data class with table residing in the database. The mapping is defined by putting annotations on the fields of the data class to specify the keys and attributes.
-
We define a repository class to define the CRUD methods using the mapping object created in the previous step.
Let us see some examples creating applications by using these two methods in the following sections.
Accessing DynamoDB with Spring Data
The primary goal of the Spring® Data project is to make it easier to build Spring-powered applications by providing a consistent framework to use different data access technologies. Spring Data is an umbrella project composed of many different sub-projects each corresponding to specific database technologies.
The Spring Data module for DynamoDB is a community module for accessing AWS DynamoDB with familiar Spring Data constructs of data objects and repository interfaces.
Initial Setup
Let us first create a Spring Boot project with the help of the Spring boot Initializr, and then open the project in our favorite IDE.
For configuring Spring Data, let us add a separate Spring Data release train BOM in our pom.xml file using this dependencyManagement block :
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-releasetrain</artifactId>
<version>Lovelace-SR1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
For adding the support for Spring Data, we need to include the module dependency for Spring Data DynamoDB into our Maven configuration. We do this by adding the modulespring-data-dynamodb in our pom.xml:
<dependency>
<groupId>com.github.derjust</groupId>
<artifactId>spring-data-dynamodb</artifactId>
<version>5.1.0</version>
</dependency>
Creating the Configuration
Next let us establish the connectivity with AWS by initializing a bean with our AWS credentials in our Spring configuration:
Configuration
@EnableDynamoDBRepositories
(basePackages = "io.pratik.dynamodbspring.repositories")
public class AppConfig {
@Bean
public AmazonDynamoDB amazonDynamoDB() {
AWSCredentialsProvider credentials =
new ProfileCredentialsProvider("pratikpoc");
AmazonDynamoDB amazonDynamoDB
= AmazonDynamoDBClientBuilder
.standard()
.withCredentials(credentials)
.build();
return amazonDynamoDB;
}
}
Here we are creating a bean amazonDynamoDB and initializing it with the credentials from a named profile.
Creating the Mapping with DynamoDB Table in a Data Class
Let us now create a DynamoDB table which we will use to store customer records from our application:
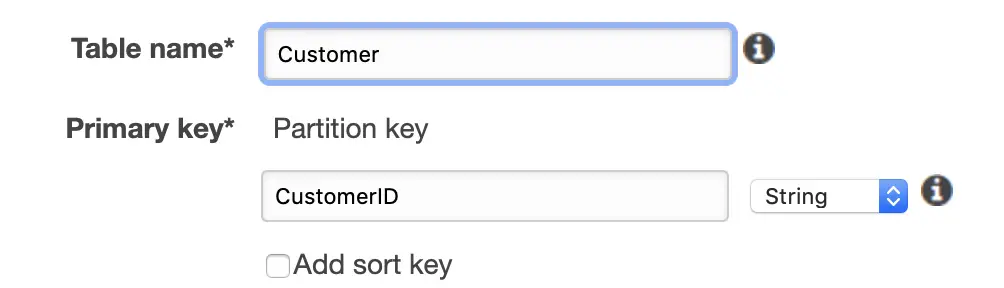
We are using the AWS console to create a table named Customer with CustomerID as the partition key.
We will next create a class to represent the Customer DynamoDB table which will contain the mapping with the keys and attributes of an item stored in the table:
@DynamoDBTable(tableName = "Customer")
public class Customer {
private String customerID;
private String name;
private String email;
// Partition key
@DynamoDBHashKey(attributeName = "CustomerID")
public String getCustomerID() {
return customerID;
}
public void setCustomerID(String customerID) {
this.customerID = customerID;
}
@DynamoDBAttribute(attributeName = "Name")
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@DynamoDBAttribute(attributeName = "Email")
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
}
We have defined the mappings with the table by decorating the class with @DynamoDBTable annotation and passing in the table name. We have used the DynamoDBHashKey attribute over the getter method of the customerID field.
For mapping the remaining attributes, we have decorated the getter methods of the remaining fields with the @DynamoDBAttribute passing in the name of the attribute.
Defining the Repository Interface
We will next define a repository interface by extending CrudRepository typed to the domain or data class and an ID type for the type of primary key. By extending the CrudRepository interface, we inherit ready to call queries like findAll(), findById(), save(), etc.
@EnableScan
public interface CustomerRepository extends
CrudRepository<Customer, String> {
}
@Service
public class CustomerService {
@Autowired
private CustomerRepository customerRepository;
public void createCustomer(final Customer customer) {
customerRepository.save(customer);
}
}
Here we have created a repository interface CustomerRepository and injected it in a service class CustomerService and defined a method createCustomer() for creating a customer record in the DynamoDB table.
We will use invoke this method a JUnit test:
@SpringBootTest
class CustomerServiceTest {
@Autowired
private CustomerService customerService;
...
...
@Test
void testCreateCustomer() {
Customer customer = new Customer();
customer.setCustomerID("CUST-001");
customer.setName("John Lennon");
customer.setEmail("john.lennon@lenno.com");
customerService.createCustomer(customer);
}
}
In our test, we are calling the createCustomer() method in our service class to create a customer record in the table.
Using the DynamoDB Enhanced Client
If we do not want to use Spring Data in our application, we can use choose to access DynamoDB with the Enhanced DynamoDB Client module of the AWS SDK for Java 2.0.
The Enhanced DynamoDB Client module provides a higher level API to execute database operations directly with the data classes in our application.
We will follow similar steps as our previous example using Spring Data.
Initial Setup
Let us create one more Spring Boot project with the help of the Spring boot Initializr. We will access DynamoDB using the Enhanced DynamoDB Client in this application.
First let us include the DynamoDB Enhanced Client module in our application:
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>dynamodb-enhanced</artifactId>
<version>2.16.74</version>
</dependency>
Here we are adding thedynamodb-enhanced module as a Maven dependency in our pom.xml.
Creating the Configuration
We will next initialize the dynamodbEnhancedClient in our Spring configuration:
@Configuration
public class AppConfig {
@Bean
public DynamoDbClient getDynamoDbClient() {
AwsCredentialsProvider credentialsProvider =
DefaultCredentialsProvider.builder()
.profileName("pratikpoc")
.build();
return DynamoDbClient.builder()
.region(Region.US_EAST_1)
.credentialsProvider(credentialsProvider).build();
}
@Bean
public DynamoDbEnhancedClient getDynamoDbEnhancedClient() {
return DynamoDbEnhancedClient.builder()
.dynamoDbClient(getDynamoDbClient())
.build();
}
}
Here we are creating a bean dynamodbClient with our AWS credentials and using this to create a bean for DynamoDbEnhancedClient.
Creating the Mapping Class
Let us now create one more DynamoDB table to store the orders placed by a customer. This time we will define a composite primary key for the Order table :
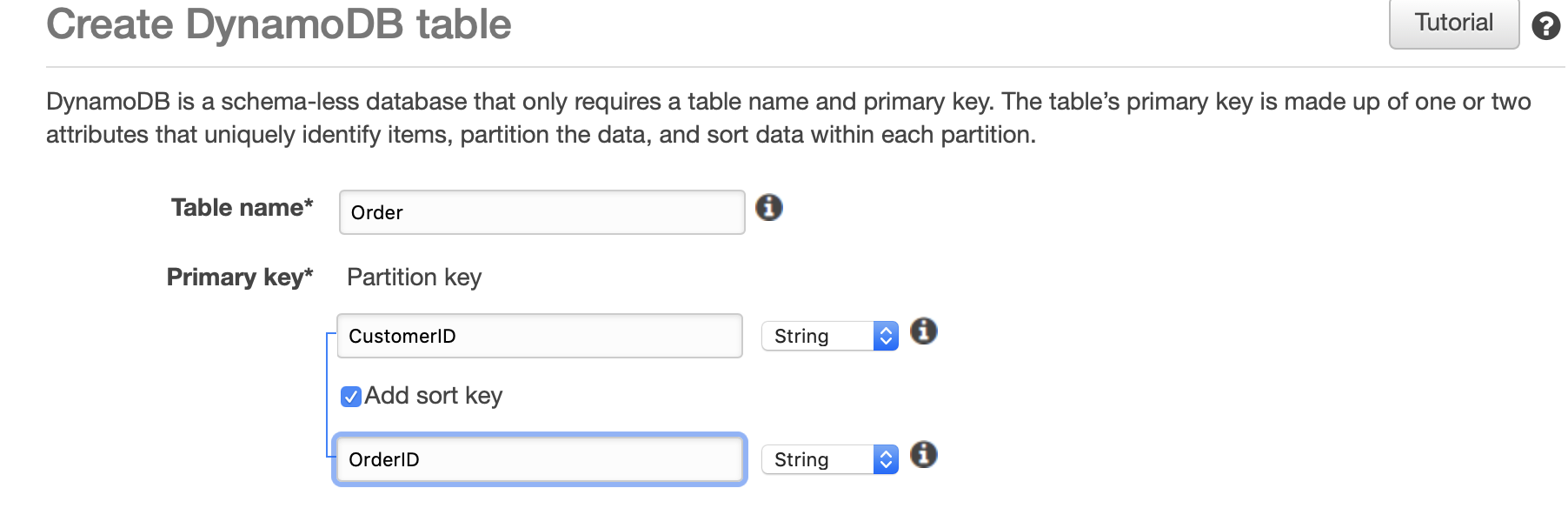
As we can see here, we are using the AWS console to create a table named Order with a composite primary key composed ofCustomerID as the partition key and OrderID as the sort key.
We will next create a Order class to represent the items in the Order table:
@DynamoDbBean
public class Order {
private String customerID;
private String orderID;
private double orderValue;
private Instant createdDate;
@DynamoDbPartitionKey
@DynamoDbAttribute("CustomerID")
public String getCustomerID() {
return customerID;
}
public void setCustomerID(String customerID) {
this.customerID = customerID;
}
@DynamoDbSortKey
@DynamoDbAttribute("OrderID")
public String getOrderID() {
return orderID;
}
public void setOrderID(String orderID) {
this.orderID = orderID;
}
...
...
}
Here we are decorating the Order data class with the @DynamoDB annotation to designate the class as a DynamoDB bean’. We have also added an annotation @DynamoDbPartitionKey for the partition key and another annotation @DynamoDbSortKey on the getter for the sort key of the record.
Creating the Repository Class
In the last step we will inject this DynamoDbEnhancedClient in a repository class and use the data class created earlier for performing different database operations:
@Repository
public class OrderRepository {
@Autowired
private DynamoDbEnhancedClient dynamoDbenhancedClient ;
// Store the order item in the database
public void save(final Order order) {
DynamoDbTable<Order> orderTable = getTable();
orderTable.putItem(order);
}
// Retrieve a single order item from the database
public Order getOrder(final String customerID, final String orderID) {
DynamoDbTable<Order> orderTable = getTable();
// Construct the key with partition and sort key
Key key = Key.builder().partitionValue(customerID)
.sortValue(orderID)
.build();
Order order = orderTable.getItem(key);
return order;
}
private DynamoDbTable<Order> getTable() {
// Create a tablescheme to scan our bean class order
DynamoDbTable<Order> orderTable =
dynamoDbenhancedClient.table("Order",
TableSchema.fromBean(Order.class));
return orderTable;
}
}
Here we are constructing a TableSchema by calling TableSchema.fromBean(Order.class) to scan our bean class Order. This will use the annotations in the Order class defined earlier to determine the attributes which are partition and sort keys.
We are then associating this Tableschema with our actual table name Order to create an instance of DynamoDbTable which represents the object with a mapped table resource Order.
We are using this mapped resource to save the order item in the save method by calling the putItem method and fetch the item by calling the getItem method.
We can similarly perform all other table-level operations on this mapped resource as shown here:
@Repository
public class OrderRepository {
@Autowired
private DynamoDbEnhancedClient dynamoDbenhancedClient;
...
...
public void deleteOrder(final String customerID,
final String orderID) {
DynamoDbTable<Order> orderTable = getTable();
Key key = Key.builder()
.partitionValue(customerID)
.sortValue(orderID)
.build();
DeleteItemEnhancedRequest deleteRequest = DeleteItemEnhancedRequest
.builder()
.key(key)
.build();
orderTable.deleteItem(deleteRequest);
}
public PageIterable<Order> scanOrders(final String customerID,
final String orderID) {
DynamoDbTable<Order> orderTable = getTable();
return orderTable.scan();
}
public PageIterable<Order> findOrdersByValue(final String customerID,
final double orderValue) {
DynamoDbTable<Order> orderTable = getTable();
AttributeValue attributeValue = AttributeValue.builder()
.n(String.valueOf(orderValue))
.build();
Map<String, AttributeValue> expressionValues = new HashMap<>();
expressionValues.put(":value", attributeValue);
Expression expression = Expression.builder()
.expression("orderValue > :value")
.expressionValues(expressionValues)
.build();
// Create a QueryConditional object that is used in
// the query operation
QueryConditional queryConditional = QueryConditional
.keyEqualTo(Key.builder().partitionValue(customerID)
.build());
// Get items in the Customer table and write out the ID value
PageIterable<Order> results =
orderTable
.query(r -> r.queryConditional(queryConditional)
.filterExpression(expression));
return results;
}
}
In this snippet, we are calling the delete, scan, and query methods on the mapped object orderTable.
Handling Nested Types
We can handle nested types by adding @DynamoDbBean annotation to the class being nested as shown in this example:
@DynamoDbBean
public class Order {
private String customerID;
private String orderID;
private double orderValue;
private Instant createdDate;
private List<Product> products;
..
..
}
@DynamoDbBean
public class Product {
private String name;
private String brand;
private double price;
...
...
}
Here we have added a nested collection of Product class to the Order class and annotated the Product class with @DynamoDbBean annotation.
A Quick Note on Source Code Organization
The source code of the example project is organized as a multi-module Maven project into two separate Maven projects under a common parent project. We have used Spring boot Initializr to generate these projects which gets generated with this parent tag in pom.xml :
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.4.5</version>
<relativePath /> <!-- lookup parent from repository -->
</parent>
We have changed this to point to the common parent project:
<parent>
<groupId>io.pratik</groupId>
<artifactId>dynamodbapp</artifactId>
<version>0.0.1-SNAPSHOT</version>
</parent>
The Spring Boot dependency is added under the dependencyManagement:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>2.4.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
Conclusion
In this article, we looked at the important concepts of AWS DynamoDB and performed database operations from two applications written in Spring Boot first with Spring Data and then using the Enhanced DynamoDB Client. Here is a summary of the things we covered:
- AWS DynamoDB is a NoSQL Key-value data store and helps us to store flexible data models.
- We store our data in a table in AWS DynamoDB. A table is composed of items and each item has a primary key and a set of attributes.
- A DynamoDB table must have a primary key which can be composed of a partition key and optionally a sort key.
- We create a secondary Index to search the DynamoDB on fields other than the primary key.
- We accessed DynamoDB with Spring Data module and then with Enhanced DynamoDB Client module of AWS Java SDK.
I hope this will help you to get started with building applications using Spring with AWS DynamoDB as the database.
You can refer to all the source code used in the article on Github.
Check Out the Book!
This article gives only a first impression of what you can do with AWS.
If you want to go deeper and learn how to deploy a Spring Boot application to the AWS cloud and how to connect it to cloud services like RDS, Cognito, and SQS, make sure to check out the book Stratospheric - From Zero to Production with Spring Boot and AWS!



