Elasticsearch is built on top of Apache Lucene and was first released by Elasticsearch N.V. (now Elastic) in 2010. According to the website of Elastic, it is a distributed open-source search and analytics engine for all types of data, including textual, numerical, geospatial, structured, and unstructured.
The operations of Elasticsearch are available as REST APIs. The primary functions are:
- storing documents in an index,
- searching the index with powerful queries to fetch those documents, and
- run analytic functions on the data.
Spring Data Elasticsearch provides a simple interface to perform these operations on Elasticsearch as an alternative to using the REST APIs directly.
Here we will use Spring Data Elasticsearch to demonstrate the indexing and search capabilities of Elasticsearch, and towards the end, build a simple search application for searching products in a product inventory.
Example Code
This article is accompanied by a working code example on GitHub.Elasticsearch Concepts
The easiest way to get introduced to Elasticsearch concepts is by drawing an analogy with a database as illustrated in this table:
| Elasticsearch | Database |
|---|---|
| Index | Table |
| Document | Row |
| Field | Column |
Any data we want to search or analyze is stored as a document in an index. In Spring Data, we represent a document in the form of a POJO and decorate it with annotations to define the mapping into an Elasticsearch document.
Unlike a database, the text stored in Elasticsearch is first processed by various analyzers. The default analyzer splits the text by common word separators like space and punctuation and also removes common English words.
If we store the text “The sky is blue”, the analyzer will store this as a document with the ‘terms’ “sky” and “blue”. We will be able to search this document with text in the form of “blue sky”, “sky”, or “blue” with a degree of the match given as a score.
Apart from text, Elasticsearch can store other types of data known as Field Type as explained under the section on mapping-types in the documentation.
Starting an Elasticsearch Instance
Before going any further, let’s start an Elasticsearch instance, which we will use for running our examples. There are numerous ways of running an Elasticsearch instance :
- Using a hosted service
- Using a managed service from a cloud provider like AWS or Azure
- DIY by installing Elasticsearch in a cluster of VMs.
- Running a Docker image
We will use the Docker image from Dockerhub, which is good enough for our demo application. Let’s start our Elasticsearch instance by running the Docker run command:
docker run -p 9200:9200 \
-e "discovery.type=single-node" \
docker.elastic.co/elasticsearch/elasticsearch:7.10.0
Executing this command will start an Elasticsearch instance listening on port 9200. We can verify the instance state by hitting the URL http://localhost:9200 and check the resulting output in our browser:
{
"name" : "8c06d897d156",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "Jkx..VyQ",
"version" : {
"number" : "7.10.0",
...
},
"tagline" : "You Know, for Search"
}
We should get the above output if our Elasticsearch instance is started successfully.
Indexing and Searching with the REST API
Elasticsearch operations are accessed via REST APIs. There are two ways of adding documents to an index:
- adding one document at a time, or
- adding documents in bulk.
The API for adding individual documents accepts a document as a parameter.
A simple PUT request to an Elasticsearch instance for storing a document looks like this:
PUT /messages/_doc/1
{
"message": "The Sky is blue today"
}
This will store the message - “The Sky is blue today” as a document in an index named “messages”.
We can fetch this document with a search query sent to the search REST API:
GET /messages/search
{
"query":
{
"match": {"message": "blue sky"}
}
}
Here we are sending a query of type match for fetching documents matching the string “blue sky”. We can specify queries for searching documents in multiple ways. Elasticsearch provides a JSON based Query DSL (Domain Specific Language) to define queries.
For bulk addition, we need to supply a JSON document containing entries similar to the following snippet:
POST /_bulk
{"index":{"_index":"productindex"}}
{"_class":"..Product","name":"Corgi Toys .. Car",..."manufacturer":"Hornby"}
{"index":{"_index":"productindex"}}
{"_class":"..Product","name":"CLASSIC TOY .. BATTERY"...,"manufacturer":"ccf"}
Elasticsearch Operations with Spring Data
We have two ways of accessing Elasticsearch with Spring Data as shown here:
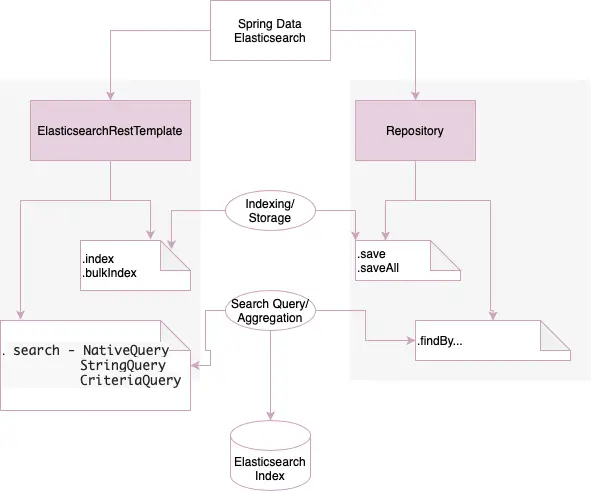
-
Repositories: We define methods in an interface, and Elasticsearch queries are generated from method names at runtime.
-
ElasticsearchRestTemplate: We create queries with method chaining and native queries to have more control over creating Elasticsearch queries in relatively complex scenarios.
We will look at these two ways in much more detail in the following sections.
Creating the Application and Adding Dependencies
Let’s first create our application with the Spring Initializr by including the dependencies for web, thymeleaf, and lombok. We are adding thymeleaf dependencies to add a user interface to the application.
We will now add the spring-data-elasticsearch dependency in our Maven pom.xml:
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-elasticsearch</artifactId>
</dependency>
Connecting to the Elasticsearch Instance
Spring Data Elasticsearch uses Java High Level REST Client (JHLC) to connect to the Elasticsearch server. JHLC is the default client of Elasticsearch. We will create a Spring Bean configuration to set this up:
@Configuration
@EnableElasticsearchRepositories(basePackages
= "io.pratik.elasticsearch.repositories")
@ComponentScan(basePackages = { "io.pratik.elasticsearch" })
public class ElasticsearchClientConfig extends
AbstractElasticsearchConfiguration {
@Override
@Bean
public RestHighLevelClient elasticsearchClient() {
final ClientConfiguration clientConfiguration =
ClientConfiguration
.builder()
.connectedTo("localhost:9200")
.build();
return RestClients.create(clientConfiguration).rest();
}
}
Here we are connecting to our Elasticsearch instance, which we started earlier. We can further customize the connection by adding more properties like enabling ssl, setting timeouts, etc.
For debugging and diagnostics, we will turn on request / response logging on the transport level in our logging configuration in logback-spring.xml:
<logger name="org.springframework.data.elasticsearch.client.WIRE" level="trace"/>
Representing the Document
In our example, we will search for products by their name, brand, price, or description. So for storing the product as a document in Elasticsearch, we will represent the product as a POJO, and decorate it with Field annotations to configure the mapping with Elasticsearch as shown here:
@Document(indexName = "productindex")
public class Product {
@Id
private String id;
@Field(type = FieldType.Text, name = "name")
private String name;
@Field(type = FieldType.Double, name = "price")
private Double price;
@Field(type = FieldType.Integer, name = "quantity")
private Integer quantity;
@Field(type = FieldType.Keyword, name = "category")
private String category;
@Field(type = FieldType.Text, name = "desc")
private String description;
@Field(type = FieldType.Keyword, name = "manufacturer")
private String manufacturer;
...
}
The @Document annotation specifies the index name.
The @Id annotation makes the annotated field the _id of our document, being the unique identifier in this index. The id field has a constraint of 512 characters.
The @Field annotation configures the type of a field. We can also set the name to a different field name.
The index by the name of productindex is created in Elasticsearch based on these annotations.
Indexing and Searching with a Spring Data Repository
Repositories provide the most convenient way to access data in Spring Data using finder methods. The Elasticsearch queries get created from method names. However, we have to be careful about not ending up with inefficient queries and putting a high load on the cluster.
Let’s create a Spring Data repository interface by extending ElasticsearchRepository interface:
public interface ProductRepository
extends ElasticsearchRepository<Product, String> {
}
Here the ProductRepository class inherits the methods like save(), saveAll(), find(), and findAll() are included from the ElasticsearchRepository interface.
Indexing
We will now store some products in the index by invoking the save() method for storing one product and the saveAll() method for bulk indexing. Before that we will put the repository interface inside a service class:
@Service
public class ProductSearchServiceWithRepo {
private ProductRepository productRepository;
public void createProductIndexBulk(final List<Product> products) {
productRepository.saveAll(products);
}
public void createProductIndex(final Product product) {
productRepository.save(product);
}
}
When we call these methods from JUnit, we can see in the trace log that the REST APIs calls for indexing and bulk indexing.
Searching
For fulfilling our search requirements, we will add finder methods to our repository interface:
public interface ProductRepository
extends ElasticsearchRepository<Product, String> {
List<Product> findByName(String name);
List<Product> findByNameContaining(String name);
List<Product> findByManufacturerAndCategory
(String manufacturer, String category);
}
On running the method findByName() with JUnit, we can see Elasticsearch queries generated in the trace logs before being sent to the server:
TRACE Sending request POST /productindex/_search? ..:
Request body: {.."query":{"bool":{"must":[{"query_string":{"query":"apple","fields":["name^1.0"],..}
Similarly, by running the method findByManufacturerAndCategory(), we can see the query generated with two query_string parameters corresponding to the two fields - “manufacturer” and “category”:
TRACE .. Sending request POST /productindex/_search..:
Request body: {.."query":{"bool":{"must":[{"query_string":{"query":"samsung","fields":["manufacturer^1.0"],..}},{"query_string":{"query":"laptop","fields":["category^1.0"],..}}],..}},"version":true}
There are numerous combinations of method naming patterns that generate a wide range of Elasticsearch queries.
Indexing and Searching with ElasticsearchRestTemplate
The Spring Data repository may not be suitable when we need more control over how we design our queries or when the team already has expertise with Elasticsearch syntax.
In this situation, we use ElasticsearchRestTemplate. It is the new client of Elasticsearch based on HTTP, replacing the TransportClient of earlier versions, which used a node-to-node binary protocol.
ElasticsearchRestTemplate implements the interface ElasticsearchOperations, which does the heavy lifting for low-level search and cluster actions.
Indexing
This interface has the methods index() for adding a single document and bulkIndex() for adding multiple documents to the index. The code snippet here shows the use of bulkIndex() for adding multiple products to the index “productindex”:
@Service
@Slf4j
public class ProductSearchService {
private static final String PRODUCT_INDEX = "productindex";
private ElasticsearchOperations elasticsearchOperations;
public List<String> createProductIndexBulk
(final List<Product> products) {
List<IndexQuery> queries = products.stream()
.map(product->
new IndexQueryBuilder()
.withId(product.getId().toString())
.withObject(product).build())
.collect(Collectors.toList());;
return elasticsearchOperations
.bulkIndex(queries,IndexCoordinates.of(PRODUCT_INDEX));
}
...
}
The document to be stored is enclosed within an IndexQuery object. The bulkIndex() method takes as input a list of IndexQuery objects and the name of the Index wrapped inside IndexCoordinates. We get a trace of the REST API for a bulk request when we execute this method:
Sending request POST /_bulk?timeout=1m with parameters:
Request body: {"index":{"_index":"productindex","_id":"383..35"}}
{"_class":"..Product","id":"383..35","name":"New Apple..phone",..manufacturer":"apple"}
..
{"_class":"..Product","id":"d7a..34",.."manufacturer":"samsung"}
Next, we use the index() method to add a single document:
@Service
@Slf4j
public class ProductSearchService {
private static final String PRODUCT_INDEX = "productindex";
private ElasticsearchOperations elasticsearchOperations;
public String createProductIndex(Product product) {
IndexQuery indexQuery = new IndexQueryBuilder()
.withId(product.getId().toString())
.withObject(product).build();
String documentId = elasticsearchOperations
.index(indexQuery, IndexCoordinates.of(PRODUCT_INDEX));
return documentId;
}
}
The trace accordingly shows the REST API PUT request for adding a single document.
Sending request PUT /productindex/_doc/59d..987..:
Request body: {"_class":"..Product","id":"59d..87",..,"manufacturer":"dell"}
Searching
ElasticsearchRestTemplate also has the search() method for searching documents in an index. This search operation resembles Elasticsearch queries and is built by constructing a Query object and passing it to a search method.
The Query object is of three variants - NativeQuery, StringQuery, and CriteriaQuery depending on how we construct the query. Let’s build a few queries for searching products.
NativeQuery
NativeQuery provides the maximum flexibility for building a query using objects representing Elasticsearch constructs like aggregation, filter, and sort. Here is a NativeQuery for searching products matching a particular manufacturer:
@Service
@Slf4j
public class ProductSearchService {
private static final String PRODUCT_INDEX = "productindex";
private ElasticsearchOperations elasticsearchOperations;
public void findProductsByBrand(final String brandName) {
QueryBuilder queryBuilder =
QueryBuilders
.matchQuery("manufacturer", brandName);
Query searchQuery = new NativeSearchQueryBuilder()
.withQuery(queryBuilder)
.build();
SearchHits<Product> productHits =
elasticsearchOperations
.search(searchQuery,
Product.class,
IndexCoordinates.of(PRODUCT_INDEX));
}
}
Here we are building a query with a NativeSearchQueryBuilder which uses a MatchQueryBuilder to specify the match query containing the field “manufacturer”.
StringQuery
A StringQuery gives full control by allowing the use of the native Elasticsearch query as a JSON string as shown here:
@Service
@Slf4j
public class ProductSearchService {
private static final String PRODUCT_INDEX = "productindex";
private ElasticsearchOperations elasticsearchOperations;
public void findByProductName(final String productName) {
Query searchQuery = new StringQuery(
"{\"match\":{\"name\":{\"query\":\""+ productName + "\"}}}\"");
SearchHits<Product> products = elasticsearchOperations.search(
searchQuery,
Product.class,
IndexCoordinates.of(PRODUCT_INDEX_NAME));
...
}
}
In this code snippet, we are specifying a simple match query for fetching products with a particular name sent as a method parameter.
CriteriaQuery
With CriteriaQuery we can build queries without knowing any terminology of Elasticsearch. The queries are built using method chaining with Criteria objects. Each object specifies some criteria used for searching documents:
@Service
@Slf4j
public class ProductSearchService {
private static final String PRODUCT_INDEX = "productindex";
private ElasticsearchOperations elasticsearchOperations;
public void findByProductPrice(final String productPrice) {
Criteria criteria = new Criteria("price")
.greaterThan(10.0)
.lessThan(100.0);
Query searchQuery = new CriteriaQuery(criteria);
SearchHits<Product> products = elasticsearchOperations
.search(searchQuery,
Product.class,
IndexCoordinates.of(PRODUCT_INDEX_NAME));
}
}
In this code snippet, we are forming a query with CriteriaQuery for fetching products whose price is greater than 10.0 and less than 100.0.
Building a Search Application
We will now add a user interface to our application to see the product search in action. The user interface will have a search input box for searching products on name or description. The input box will have a autocomplete feature to show a list of suggestions based on the available products as shown here:
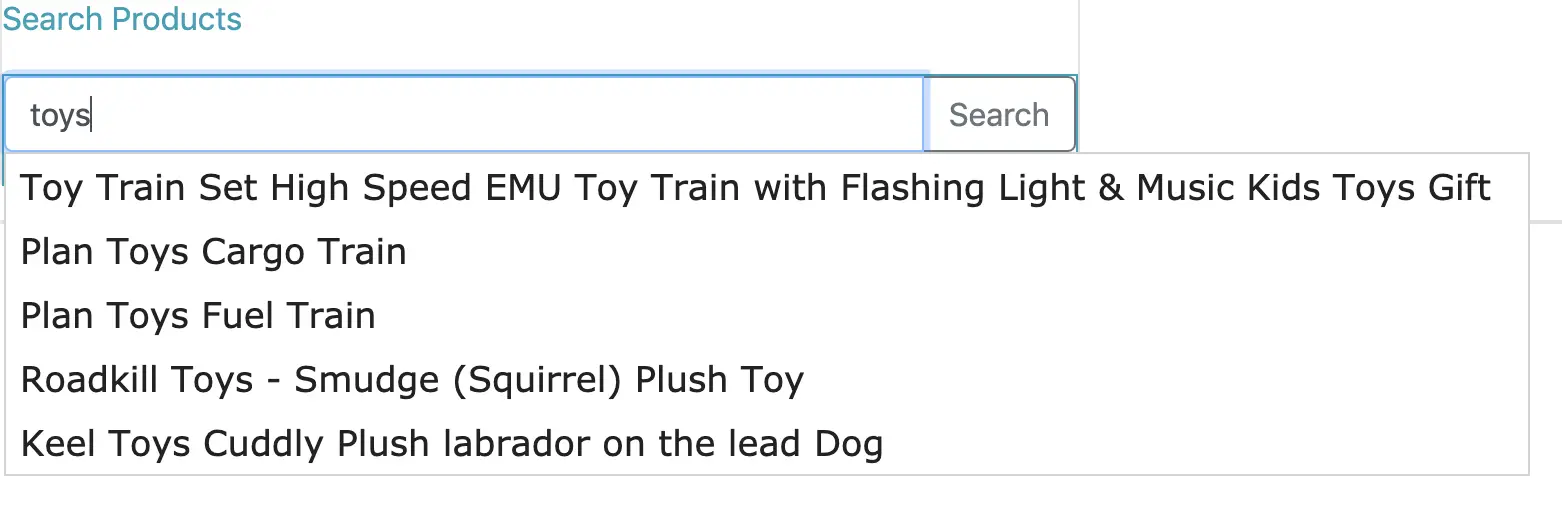
We will create auto-complete suggestions for user’s search input. Then search for products on name or description closely matching the search text entered by the user. We will build two search services to implement this use case:
- Fetch search suggestions for the auto-complete function
- Process search for searching products based on user’s search query
The Service class ProductSearchService will contain methods for search and fetching suggestions.
The full-blown application with a user interface is available in the GitHub repo.
Building the Product Search Index
The productindex is the same index we had used earlier for running the JUnit tests. We will first delete the productindex with Elasticsearch REST API, so that the productindex is created fresh during application startup with products loaded from our sample dataset of 50 fashion-line products:
curl -X DELETE http://localhost:9200/productindex
We will get the message {"acknowledged": true} if the delete operation is successful.
Now, let’s create an index for the products in our inventory. We’ll use a sample dataset of fifty products to build our index. The products are arranged as separate rows in a CSV file.
Each row has three attributes - id, name, and description. We want the index to be created during application startup. Note that in real production environments, index creation should be a separate process. We will read each row of the CSV and add it to the product index:
@SpringBootApplication
@Slf4j
public class ProductsearchappApplication {
...
@PostConstruct
public void buildIndex() {
esOps.indexOps(Product.class).refresh();
productRepo.saveAll(prepareDataset());
}
private Collection<Product> prepareDataset() {
Resource resource = new ClassPathResource("fashion-products.csv");
...
return productList;
}
}
In this snippet, we do some preprocessing by reading the rows from the dataset and passing those to the saveAll() method of the repository to add products to the index. On running the application we can see the below trace logs in the application startup.
...Sending request POST /_bulk?timeout=1m with parameters:
Request body: {"index":{"_index":"productindex"}}
{"_class":"io.pratik.elasticsearch.productsearchapp.Product","name":"Hornby 2014 Catalogue","description":"Product Desc..talogue","manufacturer":"Hornby"}
{"index":{"_index":"productindex"}}
{"_class":"io.pratik.elasticsearch.productsearchapp.Product","name":"FunkyBuys..","description":"Size Name:Lar..& Smoke","manufacturer":"FunkyBuys"}
{"index":{"_index":"productindex"}}
.
...
Searching Products with Multi-Field and Fuzzy Search
Here is how we process the search request when we submit the search request in the method processSearch():
@Service
@Slf4j
public class ProductSearchService {
private static final String PRODUCT_INDEX = "productindex";
private ElasticsearchOperations elasticsearchOperations;
public List<Product> processSearch(final String query) {
log.info("Search with query {}", query);
// 1. Create query on multiple fields enabling fuzzy search
QueryBuilder queryBuilder =
QueryBuilders
.multiMatchQuery(query, "name", "description")
.fuzziness(Fuzziness.AUTO);
Query searchQuery = new NativeSearchQueryBuilder()
.withFilter(queryBuilder)
.build();
// 2. Execute search
SearchHits<Product> productHits =
elasticsearchOperations
.search(searchQuery, Product.class,
IndexCoordinates.of(PRODUCT_INDEX));
// 3. Map searchHits to product list
List<Product> productMatches = new ArrayList<Product>();
productHits.forEach(searchHit->{
productMatches.add(searchHit.getContent());
});
return productMatches;
}
...
}
Here we perform a search on multiple fields - name and description. We also attach the fuzziness() to search for closely matching text to account for spelling errors.
Fetching Suggestions with Wildcard Search
Next, we build the autocomplete function for the search textbox. When we type into the search text field, we will fetch suggestions by performing a wild card search with the characters entered in the search box.
We build this function in the fetchSuggestions() method shown here:
@Service
@Slf4j
public class ProductSearchService {
private static final String PRODUCT_INDEX = "productindex";
public List<String> fetchSuggestions(String query) {
QueryBuilder queryBuilder = QueryBuilders
.wildcardQuery("name", query+"*");
Query searchQuery = new NativeSearchQueryBuilder()
.withFilter(queryBuilder)
.withPageable(PageRequest.of(0, 5))
.build();
SearchHits<Product> searchSuggestions =
elasticsearchOperations.search(searchQuery,
Product.class,
IndexCoordinates.of(PRODUCT_INDEX));
List<String> suggestions = new ArrayList<String>();
searchSuggestions.getSearchHits().forEach(searchHit->{
suggestions.add(searchHit.getContent().getName());
});
return suggestions;
}
}
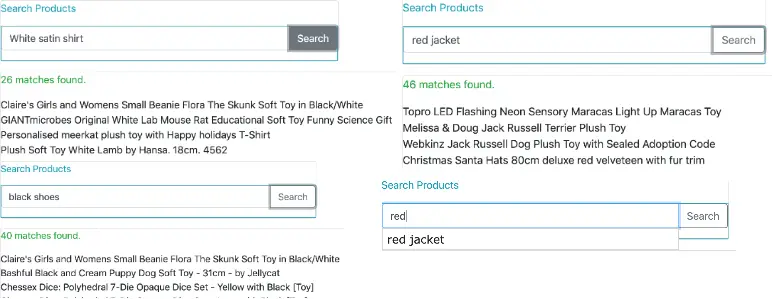
We are using a wildcard query in the form of search input text appended with * so that if we type “red” we will get suggestions starting with “red”. We are restricting the number of suggestions to 5 with the withPageable() method. Some screenshots of the search results from the running application can be seen here:
Conclusion
In this article, we introduced the main operations of Elasticsearch - indexing documents, bulk indexing, and search - which are provided as REST APIs. The Query DSL in combination with different analyzers makes the search very powerful.
Spring Data Elasticsearch provides convenient interfaces to access those operations in an application either by using Spring Data Repositories or ElasticsearchRestTemplate.
We finally built an application where we saw how the bulk indexing and search capabilities of Elasticsearch can be used in a close to real-life application.



