Rolling out new features is one of the most satisfying parts of our job. Finally, users will see the new feature we’ve worked on so hard!
Feature flags (or feature toggles) are basically if/else blocks in our application code that control whether or not a feature is available for a specific user. With feature flags, we can decide who gets to see which feature when.
This gives us fine-grained control over the rollout of new features. We can decide to activate it only for ourselves to test it or roll it out it to all users at once.
This article discusses different rollout strategies that are possible when using feature flags and when they make sense.
Dark Launch
The first rollout strategy is the “dark launch”:

We deploy a new version of our app that contains the new feature, but the feature flag for this feature is disabled for now. We can activate the feature for a subset of our users (or for all users) later.
Why should we deploy a deactivated feature? Why not just deploy the new feature without a feature flag? It would automatically be available for every user after a successful deployment, after all.
The reason that we want to use a feature flag for this is that we want to decouple the feature rollout from the deployment of the application.
There are a million things that can go wrong with a deployment. Someone might have introduced a bug that prevents the application from starting up. Or the Kubernetes cluster has a hiccup (probably due to a misplaced whitespace character in some YAML file).
Similarly, there are a million things that can go wrong with releasing a new feature. We might have forgotten to cover an edge case, overlooked a security hole, or users are using the feature in ways that we don’t want them to.
When a deployment fails, we want to know quickly what has caused the deployment to fail and fix it. If it’s not fixed quickly, the deployment pipeline is blocked and we can’t release new features at all!
You can imagine that the number of potential root causes for a deployment failure is much lower if we deploy new features behind a (deactivated) feature flag. The deactivated code can’t be the reason for the deployment failure and we can ignore the new feature in the investigation for the root cause.
So, we’ll want to release every new feature in a “dark launch” before we enable the feature for any users.
Global Rollout
Once a feature is deployed (but inactive), the simplest rollout strategy is to roll out a feature to all users at the same time:
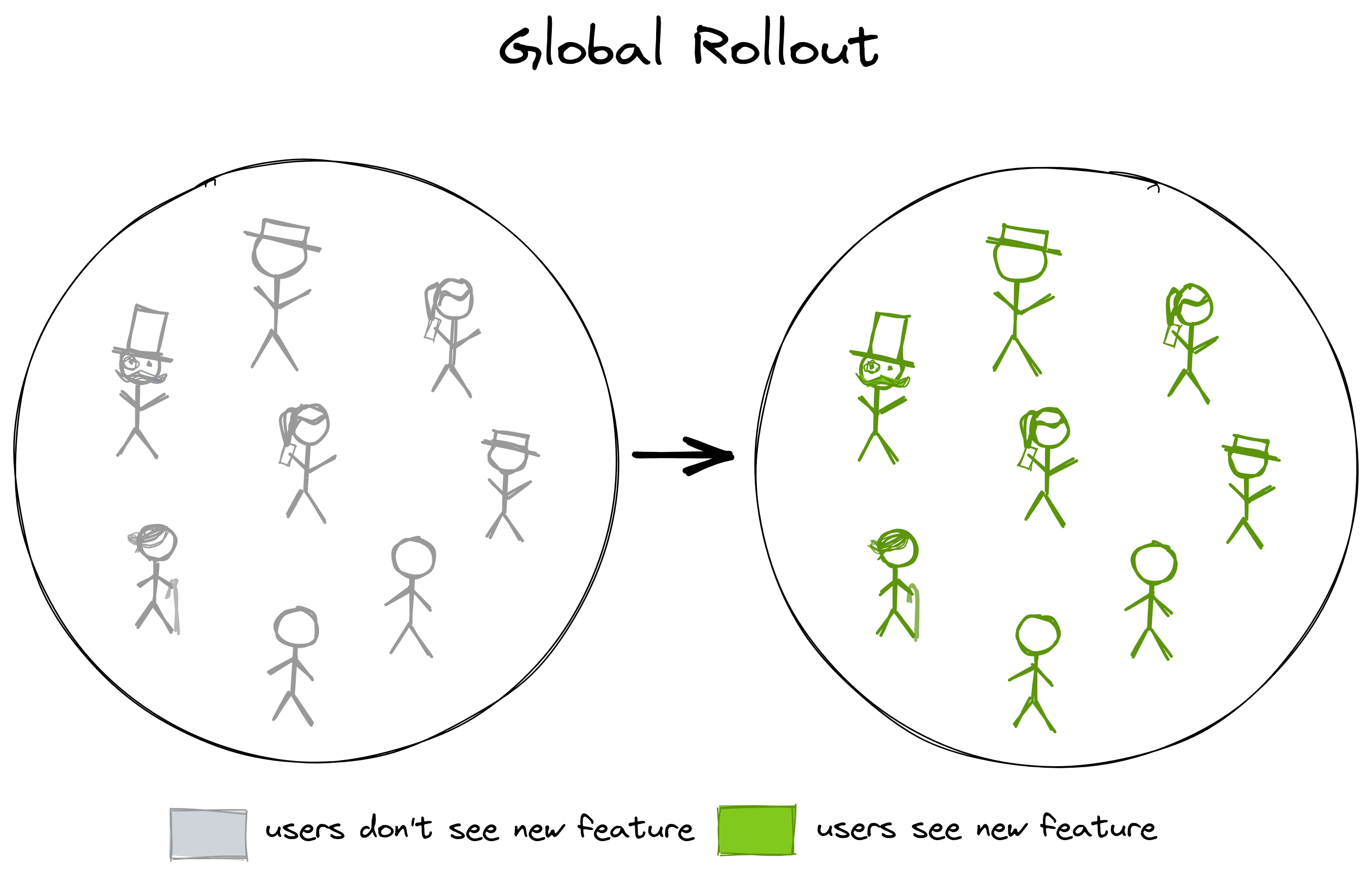
Once the deployment of the new feature has been successful, we can enable the feature flag and all users can enjoy the new feature.
We can then monitor the usage of the new feature with our logs or analytics dashboards to see if users are adopting the feature and how they’re using it. The release of the feature has been completely independent of the app’s deployment!
Issues that might have come up during the deployment will have been sorted out already when we’re rolling out the feature. If any issues come up after rolling out the feature, we know that the new feature is a likely candidate for causing them and we can investigate in this direction.
If issues with a new feature are severe enough, we might decide to deactivate the feature again, using the feature flag as a “kill switch”.
Kill Switch
Although technically the opposite of a rollout strategy, a kill switch is a valuable tool to have in case of emergency:
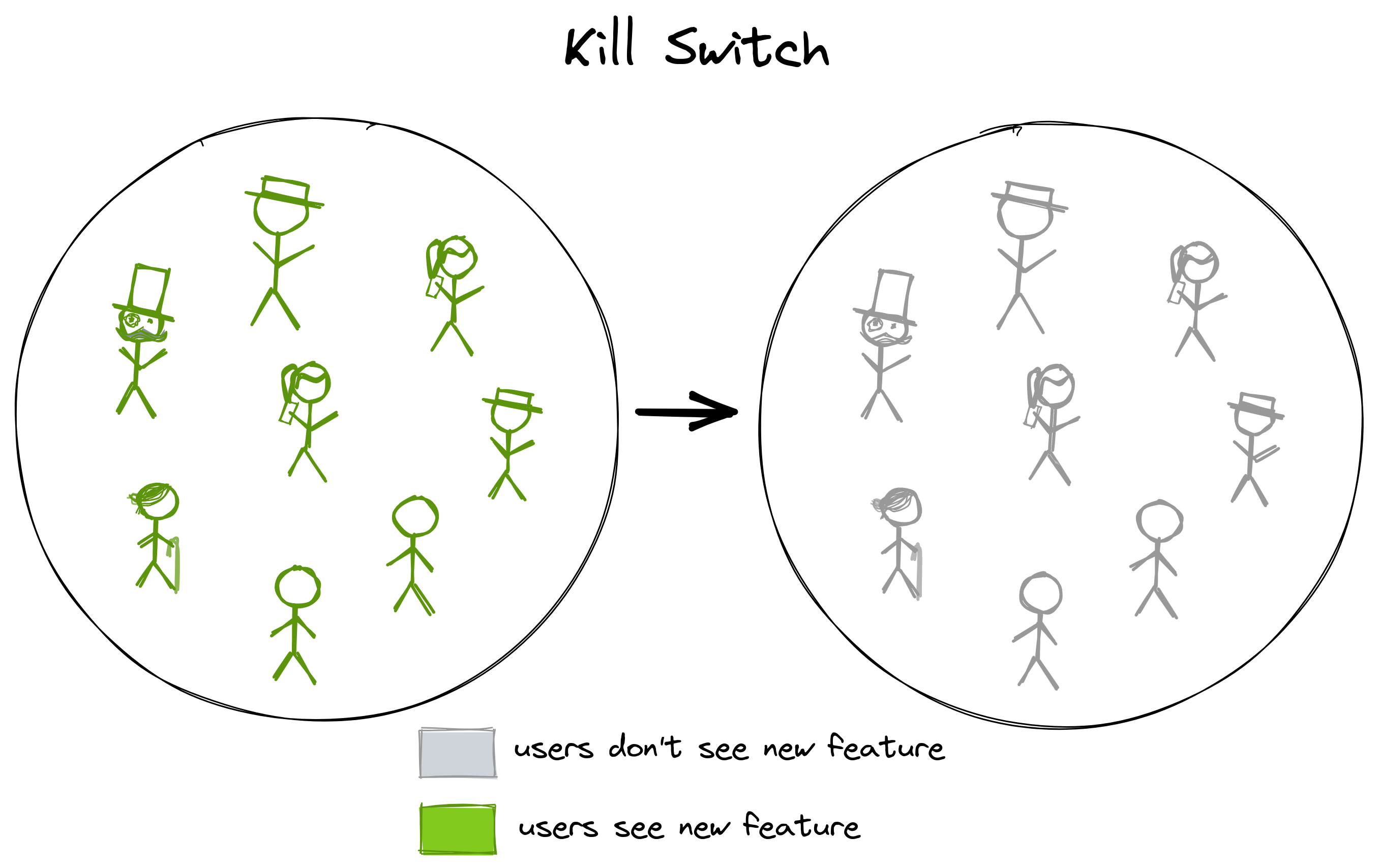
Say we have successfully rolled out a feature via a global rollout. All users are enjoying the new feature. Then, we realize that the new feature has introduced a new security vulnerability that allows hackers to siphon away our user’s data. A nightmare (not only) for the developer who built that feature!
If the feature is behind a feature flag, we can just toggle the flag to deactivate the feature and our users' data is safe again. Users might complain that they can’t use the new feature anymore, but that’s better than users complaining about being blackmailed by a hacker with access to their data.
There are lots of other potential reasons for killing a feature:
- the feature doesn’t have the expected effect,
- the feature is not working properly,
- users are unhappy with the feature,
- …
In any case, we can use a feature flag as a kill switch to deactivate the feature temporarily or permanently.
The “kill switch” option illustrates another advantage of decoupling deployments from feature rollout: if the security vulnerability from above would have been deployed without a feature flag, we would have had to roll back the application to before the vulnerability was introduced and redeploy it.
If a deployment takes 30 minutes, the security vulnerability would still be there for 30 minutes until the deployment was successful. As if that isn’t bad enough, all changes to the codebase that have been made after that vulnerable feature was added would not be available in the new deployment, because we have rolled back the code! Quite a blast radius!
Percentage Rollout
Even though activating or deactivating a feature for all users at the same time is quite powerful already, feature flags give us enough control for more sophisticated rollout strategies.
A common rollout strategy is a percentage rollout:
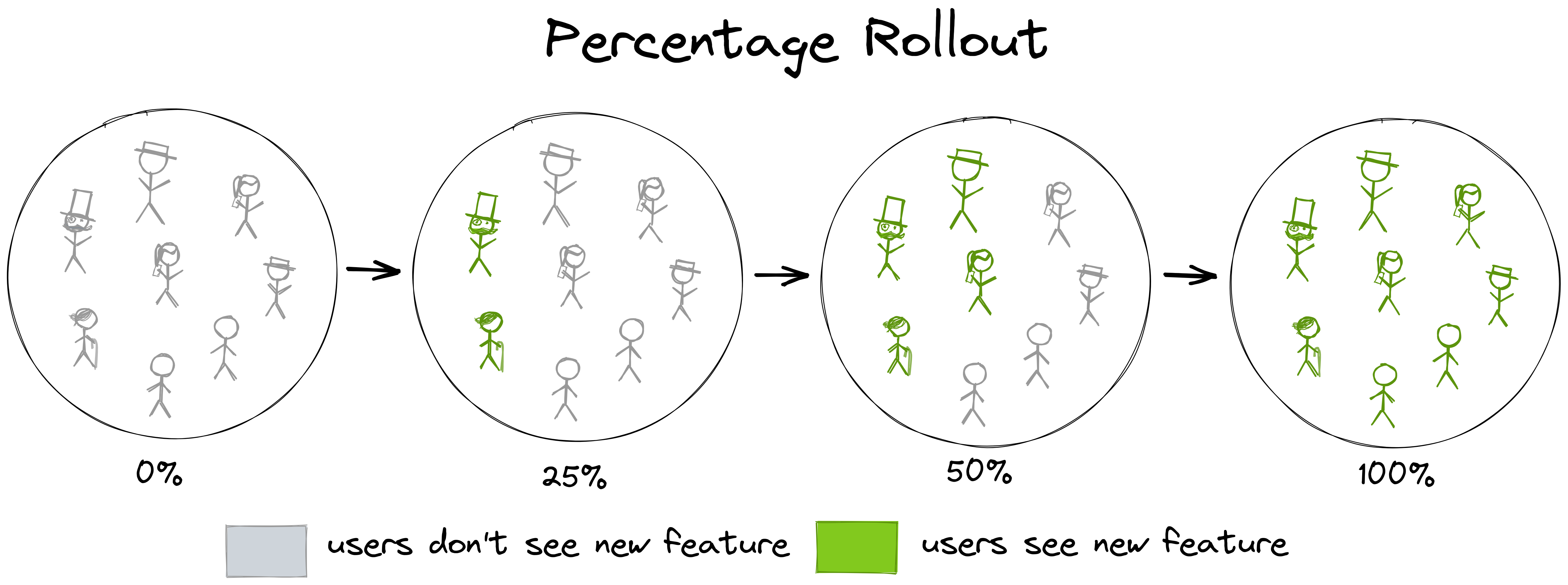
Instead of activating a feature for all users at once, we activate it in increments for a growing percentage of the users. We might decide to go in 25% increments as in the image above or we might be a bit unsure about the feature and activate it for only 5% of the users for starters to see if something goes wrong. It’s better if something goes wrong for only 5% of the users than for all users, after all.
After the feature has been active for a couple of days or so without issues, we feel confident enough to enable it for a bigger percentage of the users, until, ultimately, we enable it for all users.
Here’s another advantage of feature flags: feature flags give us confidence in rolling out features.
Even a rollout to only 5% of users can be a successful rollout! Knowing that only 5% of the users are affected if something goes wrong - and that we can turn it off at any time with the flick of a switch - gives us enormous peace of mind. If everything goes as planned, we feel confident in rolling out the feature flag to a bigger audience.
Implementing a dark launch, global rollout, and kill switch is rather easy. We just need an if/else block in our code that checks a boolean value in a database that we can switch to true or false at any time.
With a percentage rollout, however, we enter a territory where it’s not as easy to implement anymore. We can’t just evaluate the feature flag to true in 25% of the cases, because that would mean that the same user would see the feature 25% of the times they use the app and not see the feature the other 75%!
We need to split the user base into two fixed cohorts: one with 25% of the users and the other with the rest of the users. Then, we always evaluate the feature flag to true when the user is part of the first cohort and always to false if the feature is part of the second cohort.
This requires quite a sophisticated management of feature flag state per user and is not so easily implemented. This is why we should take advantage of a feature management platform like LaunchDarkly to implement feature flags.
Canary Launch
Similar to a percentage rollout is a canary launch:
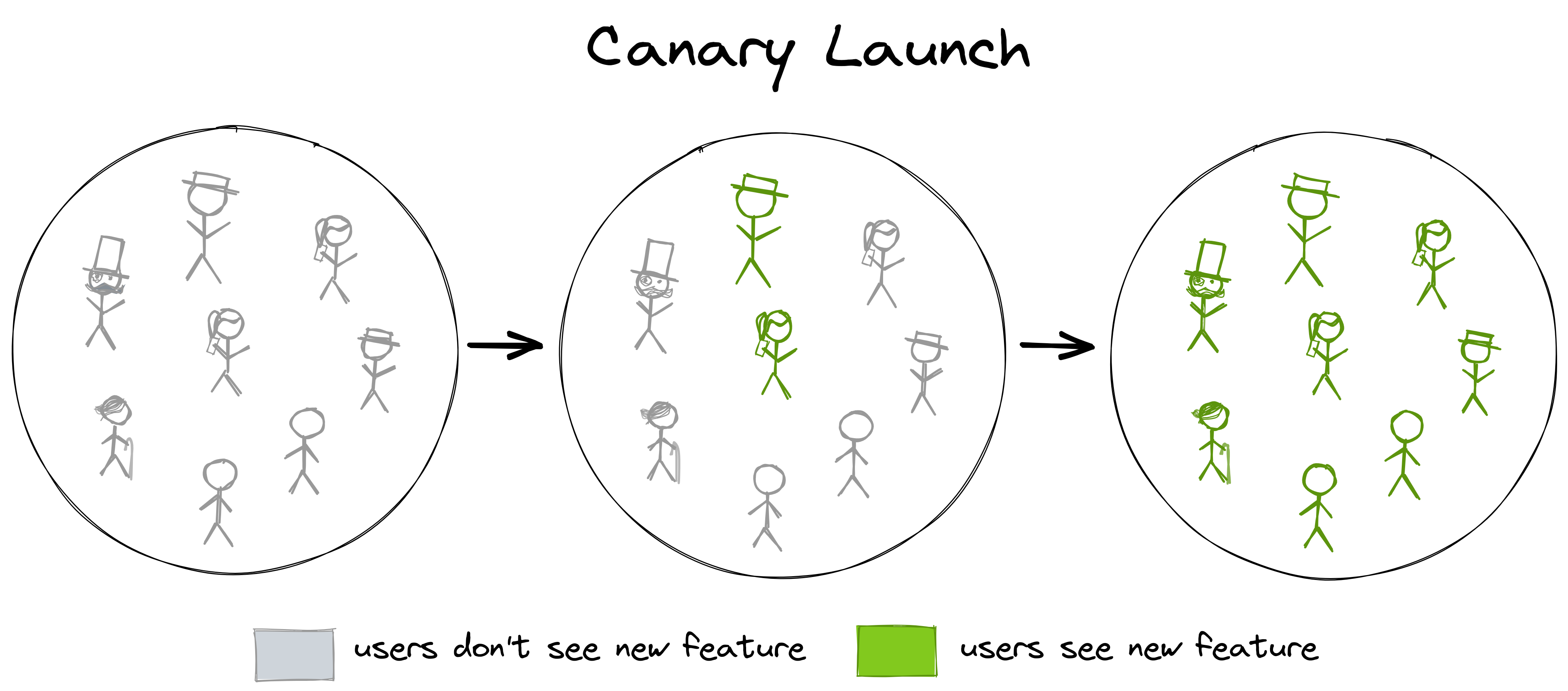
Instead of rolling out to all users at once, we only roll out to a small subset of users. This is very similar to a percentage rollout - the line between a canary launch and a percentage rollout is blurred.
The term “canary launch” comes from the rather morbid practice of taking canary birds down into mines to act as an early warning of poisonous and odorless gases. Due to their faster oxygen consumption, the birds would drop dead before any human would notice a change. When a bird died in a mine, the miners would quickly evacuate.
When we roll out a feature to a small subset of users, these users act as our “canaries” and will tell us if something is wrong (and hopefully not drop dead!). When nobody complains after a time, and the logs and metrics look good, we can enable the feature for the rest of the users.
A percentage rollout with a small starting percentage of, say, 5% may act as a canary launch. Every new feature we deploy would potentially target a different 5% of the user base, however, and we wouldn’t know how these users would react to any problems that we might introduce with new features.
It would be nice if we could roll out every new feature to the same group of “early adopter” users. This group of users is hand-picked for their early adopter mindset. We might know these users from interviews or support cases and we expect them to be understanding of any issues in an early version of a new feature.
So, instead of a percentage rollout, we might define a fixed cohort of early adopter users and use them in a canary launch before rolling out to the rest of the users.
Ring Deployment
Taking the idea of a canary launch to the next level is a strategy called “ring deployment”:
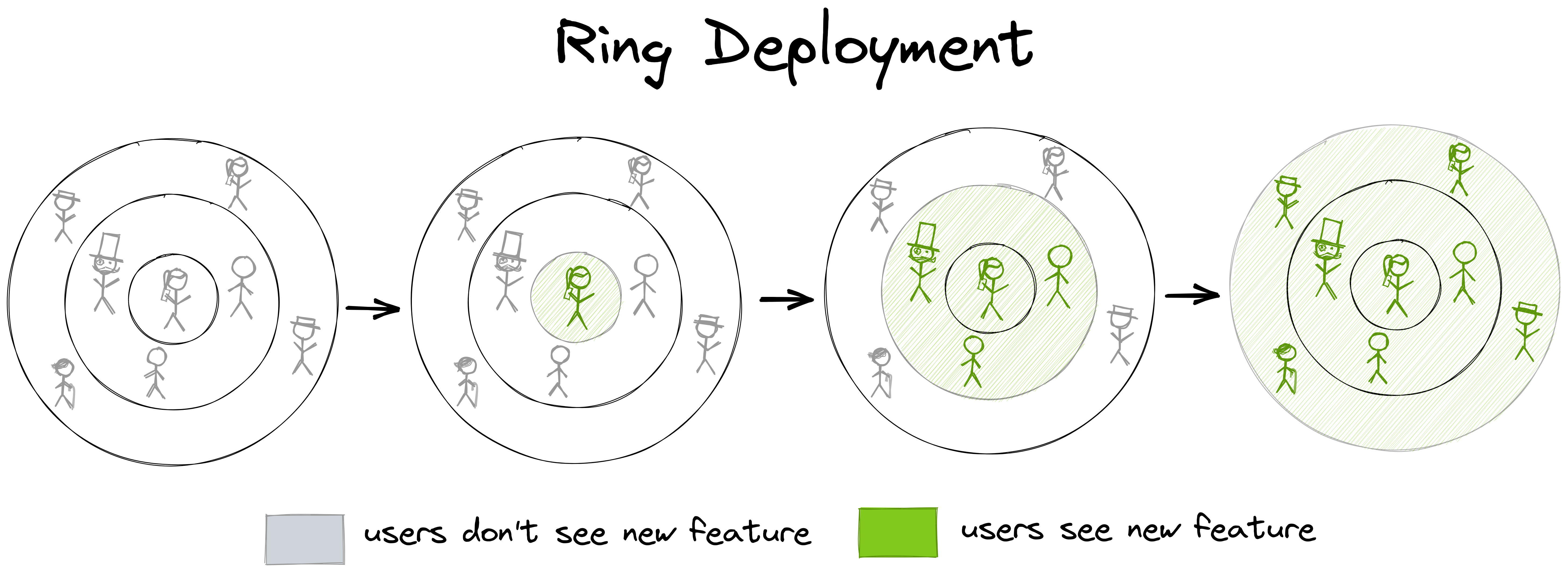
Instead of only defining one cohort for early adopter users that are comfortable with acting as “canaries”, we define multiple cohorts with ever-increasing impact. If we visualize these cohorts as rings, we see why it’s called “ring deployment”.
Then, we release a feature to one “ring” of users after another, starting with the innermost ring. We control the release with a feature flag, which we enable for one cohort after another.
We might decide that the innermost cohort consists only of friendly users within our own organization, for example. The next cohort might consist of external early adopters - the users we have already talked about in the “canary launch” section. The third cohort might be the rest of all users. We can have as many rings as make sense in our specific case.
You might wonder why it’s called ring deployment when feature flags should actually be about decoupling deployment from rolling out a feature. Indeed, a better name in this context would be “ring rollout”.
The term “ring deployment” is widely used, however, even when it’s not about deployment, but rather about feature rollout (which shouldn’t be coupled with a deployment). It stems from a time when feature flags weren’t widely adopted, and a new version of an application was actually deployed in multiple different versions to achieve the same effect. The network infrastructure would then route requests from users in one “ring” to one version, and requests from users in another “ring” to another version of the app. The term “ring deployment” stuck, and so I’m using it here for better recognition.
A/B Test
Sometimes, we’re not certain about how a certain feature would perform, so we would like to experiment with different options. In such a case, we can perform an A/B test with the help of a feature flag:
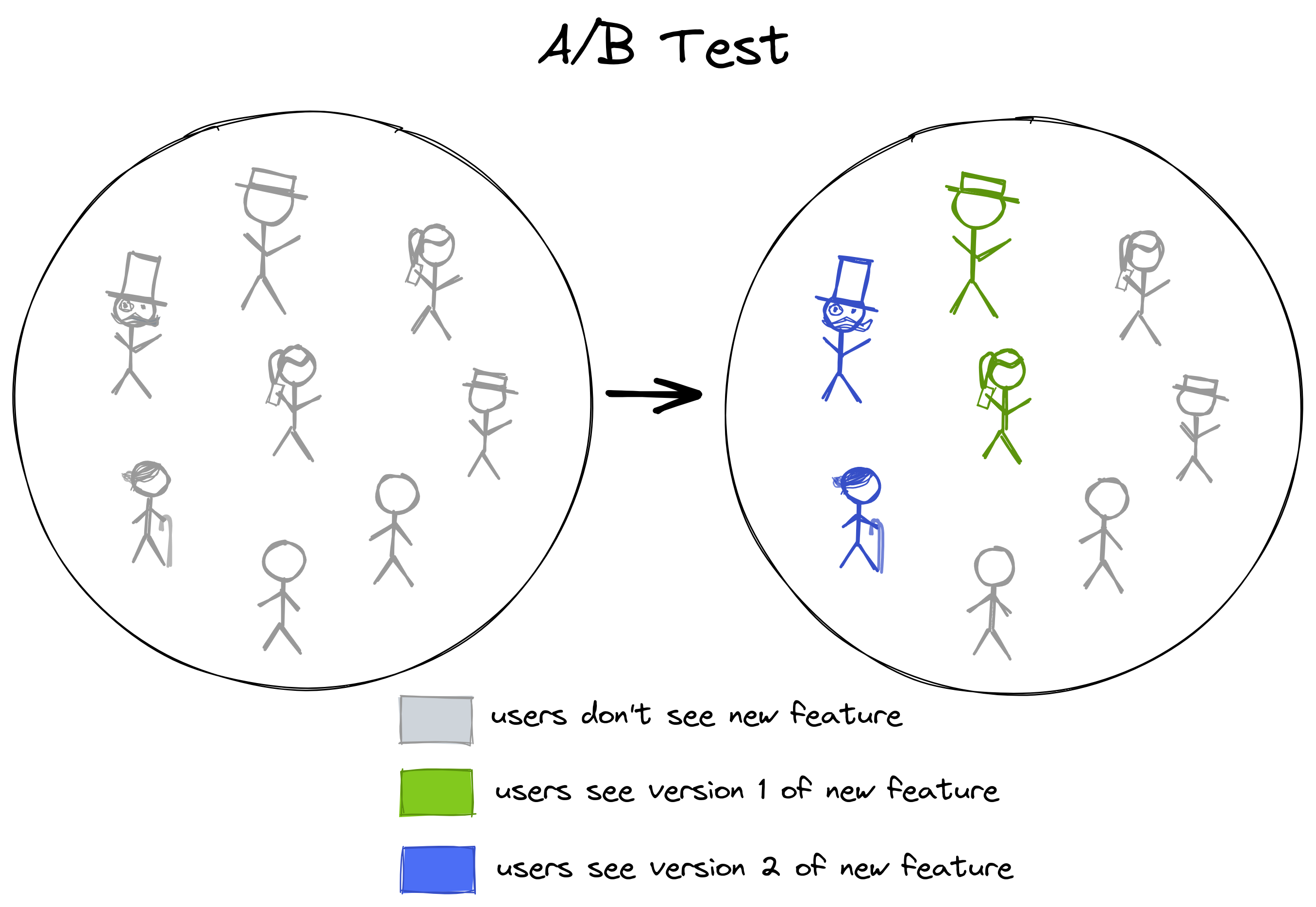
In an A/B test (also called blue/green or red/black deployment), we have two or more different versions of a feature and we want to compare their performance. “Performance” might mean technical performance (for example how fast the system responds) or business performance (for example how a feature impacts conversion rate). In any case, it’s measured by a metric we define.
To compare the performance, we want to show one version of the feature to one group of customers and another version of the feature to another group of customers.
With feature flags, we can achieve just that. We can either use one feature flag per “version” of the feature that we want to compare and then enable those features for a different group of users each.
Or, with a feature management platform like LaunchDarkly, we can create a single feature flag with multiple “variations” and define a target cohort for each of the variations. LaunchDarkly also has an “experimentation” feature that will show you the performance metrics you chose for each of the feature’s variations.
Not all features lend themselves to experiments, but if you have a case where you can compare a metric between different feature versions, an A/B test with feature flags is a very powerful tool for data-driven decisions.
Managing the Feature State
As mentioned in the article above, if you want to use rollout strategies that are more advanced than a global rollout, you probably don’t want to implement a solution for managing the state per user and feature flag yourself, but instead rely on a feature management platform like LaunchDarkly which has solutions for all the rollout strategies mentioned in this article and more.
If you’re interested in starting with a simple solution, however, you might enjoy the comparison between Togglz and LaunchDarkly. If you’re interested in tips and tricks around feature flags with Spring Boot, you might enjoy the article about feature flags with Spring Boot.



