In this article, we are going to discuss some very important commands from Git and how they make the life of developers easy - working individually or in a team. We will compare git rebase with git merge and explore some ways of using them in our Git workflow.
If you are a beginner to Git and are looking to understand the basic fork & pull workflow with Git, then you should give this article a read.
Introduction to Git
Git is an open-source distributed version control system. We can break that work down into the following pieces:
- Control System: Git can be used to store content – it is usually used to store code, but other content can also be stored.
- Version Control System: Git helps in maintaining a history of changes and supports working on the same files in parallel by providing features like branching and merging.
- Distributed Version Control System: The code is present in two types of repositories – the local repository, and the remote repository.
What is Git Merge?
Let’s first have a look at git merge. A merge is a way to put a forked history back together. The git merge command lets us take independent branches of development and combine them into a single branch.
It’s important to note that while using git merge, the current branch will be updated to reflect the merge, but the target branch remains untouched.
git merge is often used in combination with git checkout for the selection of the current branch, and git branch -d for deleting the obsolete source branch.
We use git merge for combining multiple sequences of commits into one unified history. In the most common cases, we use git merge to combine two branches.
Let’s take an example in which we will mainly focus on branch merging patterns. In the scenario which we have taken, git merge takes two commit pointers and tries to find the common base commit between them.
Once Git has found a common base commit, it will create a new “merge commit”, that will combine the changes of each queued merge commit sequence.
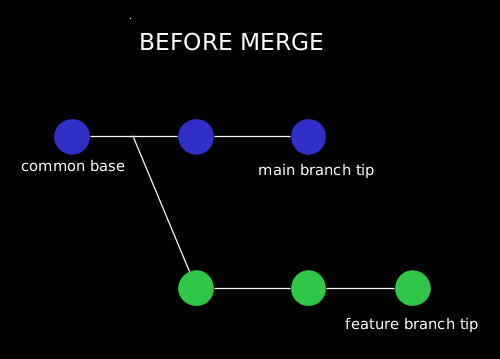
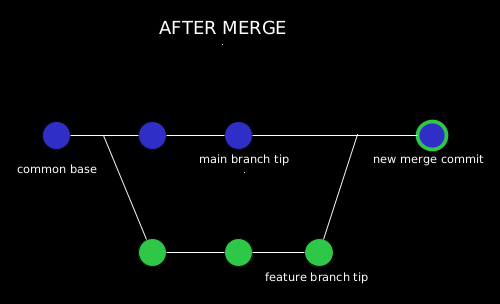
After a merge, we have a single new commit on the branch we merge into. This commit contains all the changes from the source branch.
What is Git Rebase?
Let’s have a look at the concept of git rebase. A rebase is the way of migrating or combining a sequence of commits to a new base commit. If we consider it in the context of a feature branching workflow, we can visualize it as follows:
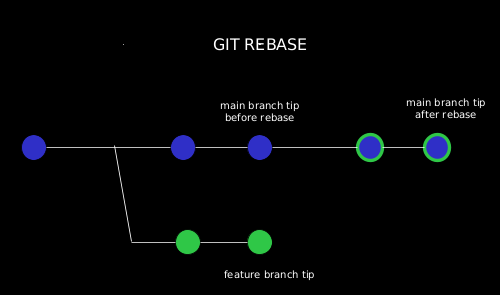
Let’s understand the working of git rebase by looking at history with a topic branch off another topic branch.
Let’s say we have branched a feature1 branch from the mainline, and added some functionality to our project, and then made a commit. Now, we branch off the feature2 branch to make some additional changes. Finally, we go back to the feature1 branch and commit a few more changes:
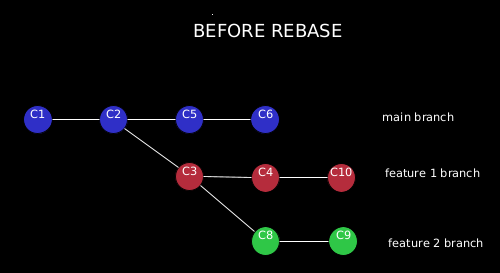
Now suppose that we have decided to merge the feature2 changes to the mainline for the release, but we also want to hold the feature1 changes until they are tested further.
With git rebase, we can “replay” the changes in the feature2 branch (that are not in the feature1 branch, i.e. C8 and C9), and then replay them on the main branch by using the –onto option of git rebase. We have to specify all the three branches names in this case because we are holding the changes from feature1 branch while replaying them in the main branch from feature2 branch:
git rebase --onto main feature1 feature2
It gives us a bit complex but a pretty cool result:
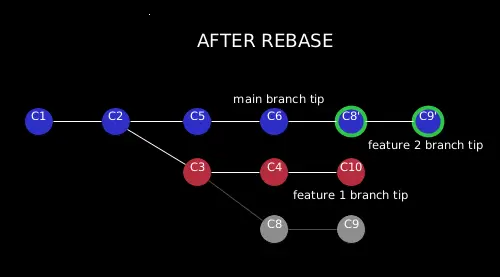
The commits from the feature2 branch have been replayed onto the main branch, and the feature2 branch now contains all the commits from the main branch plus the new commits from the feature2 branch.
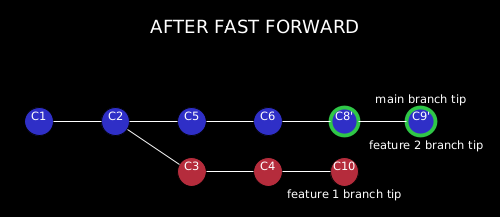
Now it’s time to fast forward our main branch so it will contain the new commits.
Fast forward is a unique instance of git rebase in which we are moving the tip of a branch to the latest commit. In our case, we want to move the tip of the main branch forward so it points to the latest commit of our feature2 branch.
We will use the following commands to do this:
git checkout main
git merge feature2
In simple words, fast-forwarding main to the feature2 branch means that previously the HEAD pointer for main branch was at ‘C6’ but after the above command it fast forwards the main branch’s HEAD pointer to the feature2 branch:
Git Rebase vs Git Merge
Now let’s go through the difference between git rebase and git merge.
Let’s have a look at git merge first:
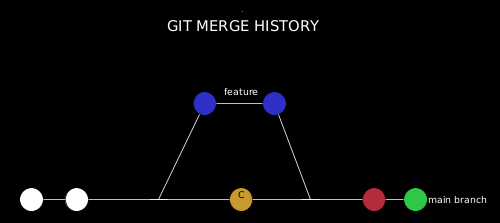
If we look at the diagram above, the golden commit is the latest commit on the base branch before the merge and the red commit is the merge commit. The merge commit has both - the latest commit in the base branch and the latest commit in the feature branch - as ancestors.
git merge preserves the ancestry of commits.
git rebase, on the other hand, re-writes the changes of one branch onto another branch without the creation of a merge commit:
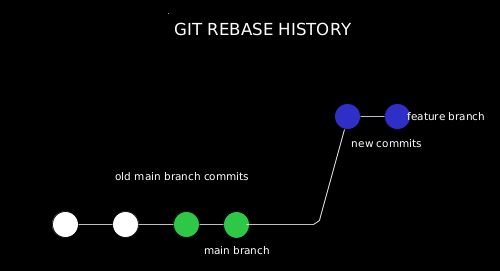
A new commit will be created on top of the branch we rebase onto, for every commit that is in the source branch, and not in the target branch. It will be just like all commits have been written on top of the main branch all along.
Arguments for Using git merge
- It’s a very simple Git methodology to use and understand.
- It helps in maintaining the original context of the source branch.
- If one needs to maintain the history graph semantically correct, then Git Merge preserves the commit history.
- The source branch commits are separated from the other branch commits. It can be very helpful in extracting the useful feature and merging later into another branch.
Arguments for Using git rebase
When a lot of developers are working on the same branch in parallel, the history can be intensely populated by lots of merge commits. It can create a very messy look of the visual charts, which can create hurdles in extracting useful information:
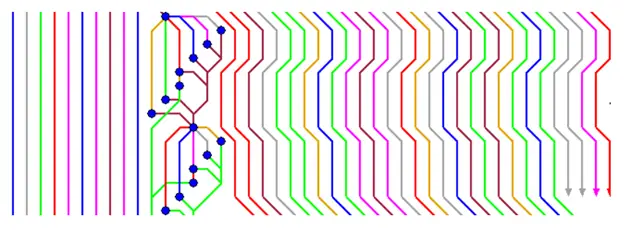
git rebase will help keep the history clean.
Choosing the Right Method
When the team chooses to go for a feature-based workflow, then git merge is the right choice because of the following reasons:
- It helps in preserving the commit history, and we need not worry about the changing history and commits.
- Avoids unnecessary git reverts or resets.
- A complete feature branch can easily reconcile changes with the help of a
merge.
Contrary to this, if we want a more linear history, then git rebase is the best option. It helps to avoid unnecessary commits by keeping the changes linear and more centralized.
We need to be very careful while applying a rebase because if it is done incorrectly, it can cause some serious issues.
Dangers of Rebasing
When it comes to rebasing and merging, most people hesitate to use git rebase as compared to git merge.
The basic purpose of git rebase and git merge is the same, i.e. they help us to bring changes from one branch into another. The difference is that git rebase re-writes the commit history:
So, if someone else checks out your branch before we rebase ours then it would be really hard to figure out what the history of each branch is.
A problem that normally occurs when more than one developer is working on the same branch is explained in the following example:
You are working with a developer on the same feature branch called login_branch.
The problem in this case with using rebase directly for login_branch by both of the developers is that both of them would be merging changes repeatedly and will get conflicts due to working on the same branch,
To avoid this problem, both developers should rebase off a common branch and once the common branch on becomes stable, one of the developers can rebase onto the main branch.
To summarize:
rebasereplays your commits on top of the new base.rebaserewrites history by creating new commits.rebasekeeps the Git history clean.
Some of the key points to keep in mind are:
rebaseonly your own local branches.- Don’t rebase public branches.
- Undo rebase with
git reflog.
Conclusion
Let’s summarize what we have discussed so far.
For repositories where multiple people work on the same branches, git rebase is not the most suitable option because the feature branch keeps on changing.
For individuals, on the other hand, rebasing provides a lot of ease. If one wants to maintain the history track, then one must go for the merging option because merging preserves the history while rebase just overwrites it.
However, if we have a complex history and we want to streamline it, then rebasing can be very useful. It can help us to remove undesirable commits, squash two or more commits into each other, also providing the option to edit commit messages (during an “interactive” rebase).
Rebase focuses on presenting one commit at a time, whereas merging focuses on presenting all at once (in a merge commit). But we should keep in mind that reverting a rebase is much more difficult than reverting a merge if there are many conflicts.



