Introduction
Java is the only (mainstream) programming language to implement the concept of checked exceptions. Ever since, checked exceptions have been the subject of controversy. Considered an innovative concept at the time (Java was introduced in 1996), nowadays they are commonly considered bad practice.
In this article, I’d like to discuss the motivation for unchecked and checked exceptions in Java, their benefits and disadvantages. Unlike many discussions on this topic, I’d like to provide a balanced view on the topic, not a mere bashing of the concept of checked exceptions.
First, we’ll dive into the motivation for checked and unchecked exceptions in Java. What does James Gosling,
the father of Java, say about the topic? Next, we’ll have a look at how exceptions work in Java and what are the
issues with checked exceptions. We’ll also discuss which type of exception should be used when. Lastly, we’ll
look at some common workarounds, like using Lombok’s @SneakyThrows.
History of Exceptions in Java and Other Languages
Exception handling in software development goes back as far as the introduction of LISP in the 1960’s. With exceptions, we can solve several problems that we might encounter in the handling of errors in our program.
The main idea behind exceptions is to separate the normal control flow from error handling. Let’s look at an example where no exceptions are used:
public void handleBookingWithoutExceptions(String customer, String hotel) {
if (isValidHotel(hotel)) {
int hotelId = getHotelId(hotel);
if (sendBookingToHotel(customer, hotelId)) {
int bookingId = updateDatabase(customer, hotel);
if (bookingId > 0) {
if (sendConfirmationMail(customer, hotel, bookingId)) {
logger.log(Level.INFO, "Booking confirmed");
} else {
logger.log(Level.INFO, "Mail failed");
}
} else {
logger.log(Level.INFO, "Database couldn't be updated");
}
} else {
logger.log(Level.INFO, "Request to hotel failed");
}
} else {
logger.log(Level.INFO, "Invalid data");
}
}
The program logic is located in just 5 or so lines of code, the rest is error handling. So instead of focusing on the main flow, the code is cluttered with error checking.
If we do not have exceptions available in our language, we can only rely on the return value of a function. Let’s rewrite our function using exceptions:
public void handleBookingWithExceptions(String customer, String hotel) {
try {
validateHotel(hotel);
sendBookingToHotel(customer, getHotelId(hotel));
int bookingId = updateDatabase(customer, hotel);
sendConfirmationMail(customer, hotel, bookingId);
logger.log(Level.INFO, "Booking confirmed");
} catch(Exception e) {
logger.log(Level.INFO, e.getMessage());
}
}
With this approach, we do not need to check return values, but the control flow is transferred to the catch block.
This approach is clearly much more readable. We have two separate flows: a happy flow and an error-handling flow.
In addition to readability, exceptions also solve the semipredicate problem. In a nutshell, the semipredicate problem occurs if a return value that indicates an error (or non-existing value) becomes a valid return value. Let’s look at a few examples to illustrate the problem:
Examples:
int index = "Hello World".indexOf("World");
int value = Integer.parseInt("123");
int freeSeats = getNumberOfAvailableSeatsOfFlight();
The indexOf() method returns -1 if the substring isn’t found. Of course, -1 can never be a valid index, so there’s no
issue here. However, all possible return values of parseInt() are valid integers. That means we do not have a
special return value in case of an error available. The last method, getNumberOfAvailableSeatsOfFlight() could
even lead to a hidden issue. We could define -1 as the return value for an error, or no information available. That might
seem reasonable at first glance. However, it might turn out later that a negative number means the number of people on a waiting list.
Exceptions would solve this problem more elegantly.
How Do Exceptions Work in Java?
Before going into a discussion a whether or not to use checked exceptions, let’s briefly recap how exceptions work in Java. The diagram shows the class hierarchy for exceptions:
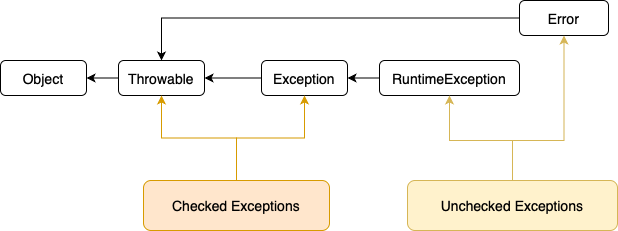
RuntimeException extends Exception and the Error extends Throwable. RuntimeException and Error are so-called unchecked exceptions, meaning that they don’t need to be handled by the calling code (i.e. they don’t need to be “checked”). All other classes that extend Throwable (usually via Exception)
are checked exceptions, meaning that the compiler expects them to be handled by the calling code (i.e. they must be “checked”).
Everything, checked or not, that extends from Throwable can be caught in a catch-block.
Lastly, it’s important to note that the concept of checked and unchecked exceptions is a Java compiler feature. The JVM itself doesn’t know the difference, all exceptions are unchecked. That’s why other JVM languages do not need to implement the feature.
Before we start our discussion about wether or not to use checked exceptions, let’s briefly recap the difference between the two types of exceptions.
Checked Exceptions
Checked exceptions need to be surrounded by a try-catch block or the calling method needs to declare
the exception in its signature. Since the constructor of the Scanner class throws a FileNotFoundException exception,
which is a checked exception, the following code does not compile:
public void readFile(String filename) {
Scanner scanner = new Scanner(new File(filename));
}
We get a compilation error:
Unhandled exception: java.io.FileNotFoundException
We have two option to fix the problem. We can add the exception to the method signature:
public void readFile(String filename) throws FileNotFoundException {
Scanner scanner = new Scanner(new File(filename));
}
Or we can handle the exception in-place with a try-catch block:
public void readFile(String filename) {
try {
Scanner scanner = new Scanner(new File(filename));
} catch (FileNotFoundException e) {
// handle exception
}
}
Unchecked Exceptions
In case of unchecked exceptions, we do not need to do anything. The NumberFormatException which can be thrown
by Integer.parseInt is a runtime exception, so the following code compiles:
public int readNumber(String number) {
return Integer.parseInt(callEndpoint(number));
}
However, we can still choose to handle the exception, so the following code compiles as well:
public int readNumber(String number) {
try {
return Integer.parseInt(callEndpoint(number));
} catch (NumberFormatException e) {
// handle exception
return 0;
}
}
Why Should We Use Checked Exceptions?
If we want to understand the motivation behind checked exceptions, we need to look at the history of Java. The language was created with a focus on robustness and networking.
The best way of putting it is probably a quote by James Gosling (the creator of Java) himself “You can’t accidentally say, ‘I don’t care.’ You have to explicitly say, ‘I don’t care.'” The quote is taken from an interesting interview with James Gosling, where he discusses checked exceptions in great detail. I highly recommend reading it.
In the book Masterminds of Programming, James also talks about exceptions. “People tend to ignore to check the return code”.
This again underlines the motivation for checked exceptions. As a general rule, an unchecked exception should occur when the error is due to a programming fault or a faulty input. A checked exception should be used if the programmer cannot do anything at the time of writing the code. A good example of the latter case is a networking issue. It’s out of the hands of the developer to solve the problem, still, the program should handle the situation appropriately - that could be terminating the program, doing a retry, or simply display an error message.
What Are the Issues with Checked Exceptions?
Now that we understand the motivation behind checked and unchecked exceptions, let’s look at some of the problems that checked exceptions can introduce in our codebase.
Checked Exceptions Do Not Scale Well
One of the main arguments against checked exceptions is code scalability and maintainability. A change in a method’s list
of exceptions breaks all method call in the calling chain, starting from the calling method
up to the method that eventually implements a try-catch to handle the exception.
As an example, let’s say we call a method libraryMethod() that is part of an external library:
public void retrieveContent() throws IOException {
libraryMethod();
}
Here, the method libraryMethod() itself is from a dependency, for example, a library that handles REST calls to an external
system for us. Its implementation would be:
public void libraryMethod() throws IOException {
// some code
}
In the future, we decide to use a new version of the library, or even replace the library with another one. Even though, the functionality is similar, the method in the new library throws two exceptions:
public void otherSdkCall() throws IOException, MalformedURLException {
// call method from SDK
}
As we have two checked exceptions, the declaration of our method needs to change as well:
public void retrieveContent() throws IOException, MalformedURLException {
sdkCall();
}
For a small codebase, this might not be a big deal, however, for large codebases, this would require quite some refactoring. Of course, we could also directly handle the exception inside our method:
public void retrieveContent() throws IOException {
try {
otherSdkCall();
} catch (MalformedURLException e) {
// do something with the exception
}
}
With this approach, we introduce an inconsistency in our codebase as we handle one exception immediately and defer the handling of the other.
Exception Propagation
An argument very similar to scalability is the way checked exceptions propagate through the calling stack. If we follow the “throw early, catch late” principle, we need to add a throws clause (a) to every calling method:

Unchecked exceptions (b) on the contrary only need to be declared where they actually occur and once more in the place where we want to handle them. They nicely propagate through the stack automatically until they reach the place where they are actually handled.
Unnecessary Dependencies
Checked dependencies also introduce dependencies that aren’t necessary with unchecked exceptions.
Let’s look again at scenario (a) where we added the IOException in three different places. If methodA(),
methodB(), and methodC() are located in different classes, so we’ll have a dependency on the exception class
in all involved classes. If we had used an unchecked exception, we’d only have this dependency in methodA() and methodC().
The class or module where methodB() doesn’t even need to know about the exception.
Let’s illustrate this idea with an example. Imagine you travel back home from vacation. You check out at the reception of the hotel, go to the train station by bus, then transfer trains once, and, back in your hometown, you take another bus to go from the station to your home. Back home, you realize that you left our phone at the hotel. Before you start to unpack, you enter the “exception” flow, and take the bus and train back to the hotel to get your phone. In this case, you do everything you did before in reverse order (like moving up the stack trace when an exception occurs in Java) until you arrive at the hotel. Obviously, neither the bus driver nor the train operator need to know about the “exception”, they simply do their job. Only at the reception, the starting point of the “travel home” flow, we need to ask if someone has found the phone.
Bad Coding Practises
Of course, as professional software developers, we should never choose convenience over good coding practices. However, it can often be tempting to quickly introduce the below three patterns when it comes to checked exceptions. Typically the idea is to take care of it later. Well, we all know how that ends. Another common statement is “I want to write my code for the happy flow, not be bothered with exceptions”. There are three such patterns that I’ve seen quite frequently.
The first one is the catch-all exception:
public void retrieveInteger(String endpoint) {
try {
URL url = new URL(endpoint);
int result = Integer.parseInt(callEndpoint(endpoint));
} catch (Exception e) {
// do something with the exception
}
}
We simply catch all possible exceptions instead of handling the different exceptions separately:
public void retrieveInteger(String endpoint) {
try {
URL url = new URL(endpoint);
int result = Integer.parseInt(callEndpoint(endpoint));
} catch (MalformedURLException e) {
// do something with the exception
} catch (NumberFormatException e) {
// do something with the exception
}
}
Of course, this isn’t necessarily a bad practice in general. It’s an appropriate thing to do if we only want to log the exception, or as a final safety mechanism in a Spring Boot @ExceptionHandler.
The second pattern is empty catch blocks:
public void myMethod() {
try {
URL url = new URL("malformed url");
} catch (MalformedURLException e) {}
}
This approach obviously circumvents the entire idea of checked exceptions. Also, it completely hides the exception as our program continues without giving us any information about what happened.
The third one is to simply print the stack trace and continue as if nothing had happened:
public void consumeAndForgetAllExceptions(){
try {
// some code that can throw an exception
} catch (Exception ex){
ex.printStacktrace();
}
}
Additional Code Only to Satisfy the Signature
Sometimes we know for sure that an exception cannot be thrown unless we deal with a programming mistake. Let’s consider the following example:
public void readFromUrl(String endpoint) {
try {
URL url = new URL(endpoint);
} catch (MalformedURLException e) {
// do something with the exception
}
}
MalformedURLException is a checked exception and it’s thrown when the given string isn’t of a valid URL format.
The important thing to note is, that the exception is thrown if the URL format is not valid, it does not mean
that the URL actually exists and can be reached.
Even if we validated the format before:
public void readFromUrl(@ValidUrl String endpoint)
Or if we’ve hardcoded it:
public static final String endpoint = "http://www.example.com";
The compiler still forces us to handle the exception. We need to write two lines of “useless” code, only because there’s a checked exception.
If we cannot write code to trigger a certain exception to be thrown, we cannot test for it, hence test coverage will decrease.
Interestingly, when we want to parse a string to an integer, we are not forced to handle the exception:
Integer.parseInt("123");
The parseInt method throws a NumberFormatException, an unchecked exception, if the provided string isn’t a valid integer.
Lambdas and Exceptions
Checked exceptions also do not always work nicely with lambda expressions. Let’s look at an example:
public class CheckedExceptions {
public static String readFirstLine(String filename) throws FileNotFoundException {
Scanner scanner = new Scanner(new File(filename));
return scanner.next();
}
public void readFile() {
List<String> fileNames = new ArrayList<>();
List<String> lines = fileNames.stream().map(CheckedExceptions::readFirstLine).toList();
}
}
As our method readFirstLine() throws a checked exception, we’ll get a compilation error:
Unhandled exception: java.io.FileNotFoundException in line 8.
If we attempt to correct the code with a surrounding try-catch:
public void readFile() {
List<String> fileNames = new ArrayList<>();
try {
List<String> lines = fileNames.stream()
.map(CheckedExceptions::readFirstLine)
.toList();
} catch (FileNotFoundException e) {
// handle exception
}
}
We still get a compilation error, because we cannot propagate a checked exception inside the lambda to the outside. We have to handle the exception inside the lambda expression and throw a runtime exception:
public void readFile() {
List<String> lines = fileNames.stream()
.map(filename -> {
try{
return readFirstLine(filename);
} catch(FileNotFoundException e) {
throw new RuntimeException("File not found", e);
}
}).toList();
}
Unfortunately, this makes the use of static method references impossible if they throw a checked exception. Alternatively, we could have the lambda expression return an error message that is added to the result:
public void readFile() {
List<String> lines = fileNames.stream()
.map(filename -> {
try{
return readFirstLine(filename);
} catch(FileNotFoundException e) {
return "default value";
}
}).toList();
}
However, the code still looks rather cluttered.
What we can do is pass an unchecked exception from inside a lambda and catch it from the calling method:
public class UncheckedExceptions {
public static int parseValue(String input) throws NumberFormatException {
return Integer.parseInt(input);
}
public void readNumber() {
try {
List<String> values = new ArrayList<>();
List<Integers> numbers = values.stream()
.map(UncheckedExceptions::parseValue)
.toList();
} catch(NumberFormatException e) {
// handle exception
}
}
}
Here, we need to be aware of a crucial difference between the earlier example with the checked exception and the example with the unchecked exception. In the case of the unchecked exception, the processing of the stream will continue with the next element, whereas in the case of the unchecked exception, the processing will end and no further elements will be processed. Which of the two we want, obviously depends on our use case.
Alternative Ways to Handle Checked Exceptions
Wrap a Checked Exception in an Unchecked Exception
We can avoid adding a throws clause to all methods up the calling stack by wrapping a checked exception in an unchecked exception. Instead of having our method throw a checked exception:
public void myMethod() throws IOException {}
We can wrap it in an unchecked exception:
public void myMethod(){
try {
// some logic
} catch(IOException e) {
throw new MyUnchckedException("A problem occurred", e);
}
}
Ideally, we apply exception chaining. This ensures that the original exception is not hidden. We can see exception chaining in line 5, where the original exception is passed as a parameter to the new exception. This technique has been possible with almost all core Java exceptions since the early versions of Java.
Exception chaining is a common approach with many popular frameworks like Spring or Hibernate. Both frameworks moved from checked to unchecked exceptions and wrap checked exceptions that are not part of the framework in their own runtime exceptions. A good example is Spring’s JDBC template which translates all JDBC-specific exceptions into unchecked exceptions that are part of the Spring framework.
Lombok @SneakyThrows
Project Lombok provides us with an annotation that removes the need for exception chaining. Instead of adding a throws clause to our method:
public void beSneaky() throws MalformedURLException {
URL url = new URL("http://test.example.org");
}
We can add @SneakyThrows and our code will compile:
@SneakyThrows
public void beSneaky() {
URL url = new URL("http://test.example.org");
}
However, it’s important to understand that @SneakyThrows does not cause the MalformedURLException to behave exactly
like a runtime exception. We won’t be able to catch it anymore and the following code won’t compile:
public void callSneaky() {
try {
beSneaky();
} catch (MalformedURLException e) {
// handle exception
}
}
As @SneakyThrows removes the exception and MalformedURLException is still considered a checked exception,
we’ll get a compiler error in line 4:
Exception 'java.net.MalformedURLException' is never thrown in the corresponding try block
Performance
During my research for this article, I came across a few discussions about the performance of exceptions. Is there a difference in performance between checked and unchecked? There isn’t. It’s a compile-time feature.
However, there’s a significant performance difference whether or not we include the full stack trace in the exception:
public class MyException extends RuntimeException {
public MyException(String message, boolean includeStacktrace) {
super(message, null, !includeStacktrace, includeStacktrace);
}
}
Here, we add a flag to the constructor of our custom exception. The flag specifies if we want to include the full stack trace or not. Building up the stack trace makes our program slower in case the exception is thrown. So if performance is critical, exclude the trace.
Some Guidelines
How to handle exceptions in our software is an integral part of our craft and highly depends on the specific use case. Before we finish our discussion, here are three high-level guidelines which I believe are (almost) always true.
- Use checked exceptions if it’s not a programming mistake or if the program can do something useful to recover.
- Use a runtime exception if it’s a programming mistake or if the program cannot do anything to recover.
- Avoid empty catch blocks.
Conclusion
In this article, we’ve gained quite some insights into exceptions in Java. Why were they introduced into the language, when should we use checked, when unchecked exceptions? We’ve learned about the drawbacks of checked exceptions and why they are nowadays considered bad practice - keeping in mind that there are many exceptions that prove the rule.



