Amazon Kinesis is a family of managed services for collecting and processing streaming data in real-time. Stream processing platforms are an integral part of the Big Data ecosystem.
Examples of streaming data are data collected from website click-streams, marketing, and financial information, social media feeds, IoT sensors, and monitoring and operational logs.
In this article, we will introduce Amazon Kinesis and understand different aspects of processing streaming data like ingestion, loading, delivery, and performing analytic operations using the different services of the Kinesis family: Kinesis Data Stream, Kinesis Data Firehose, Kinesis Data Analytics, and Kinesis Video Streams.
Example Code
This article is accompanied by a working code example on GitHub.What is Streaming Data?
Streaming data is data that is generated continuously (in a stream) by multiple data sources which typically send the data records simultaneously. Due to its continuous nature, streaming data is also called unbounded data as opposed to bounded data handled by batch processing systems.
Streaming data includes a wide variety of data such as:
- log files generated by customers using their mobile devices or web applications
- customer activity in e-commerce sites
- in-game player activity
- feeds from social media networks
- real-time market data from financial exchanges
- location feeds from geospatial services
- telemetry data from connected devices
Streaming data is processed sequentially and incrementally either by one record at a time or in batches of records aggregated over sliding time windows.
What is Amazon Kinesis?
Amazon Kinesis is a fully managed streaming data platform for processing streaming data. It provides four specialized services roughly classified based on the type and stages of processing of streaming data:
-
Kinesis Data Streams (KDS): The Kinesis Data Streams service is used to capture streaming data produced by various data sources in real-time. Producer applications write to the Kinesis Data Stream and consumer applications connected to the stream read the data for different types of processing.
-
Kinesis Data Firehose (KDF): With Kinesis Data Firehose, we do not need to write applications or manage resources. We configure data producers to send data to Kinesis Data Firehose, and it automatically delivers the data to the specified destination. We can also configure Kinesis Data Firehose to transform the data before delivering it.
-
Kinesis Data Analytics (KDA): With Kinesis Data Analytics we can process and analyze streaming data. It provides an efficient and scalable environment to run applications built using the Apache Flink framework which provides useful operators like map, filter, aggregate, window, etc for querying streaming data.
-
Kinesis Video Streams (KVS): Kinesis Video Streams is a fully managed service that we can use to stream live media from video or audio capturing devices to the AWS Cloud, or build applications for real-time video processing or batch-oriented video analytics.
Let us understand these services in the following sections.
Kinesis Data Streams
The Kinesis Data Streams service is used to collect and store streaming data as soon as it is produced (in real-time).
The streaming data is collected by producer applications from various data sources and continually pushed to a Kinesis Data Stream. Similarly, the consumer applications read the data from the Kinesis Data Stream and process the data in real-time as shown below:
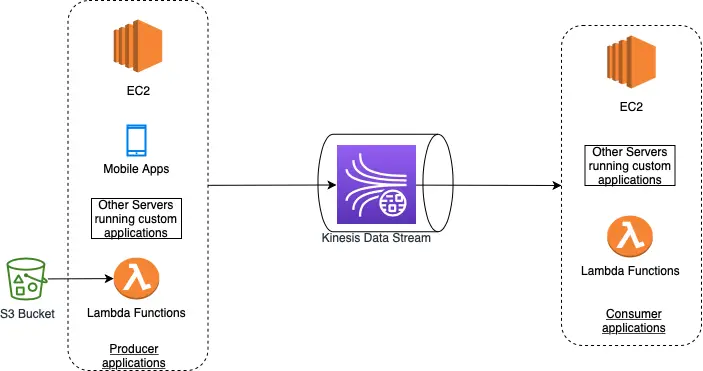
Examples of consumer applications are custom applications running on EC2 instances, EMR clusters, Lambda functions, or a Kinesis Data Firehose delivery stream which can use another AWS service such as DynamoDB, Redshift, or S3 to store the results of their processing.
As part of the processing, the consumer applications can store their results using another AWS service such as DynamoDB, Redshift, or S3. The consumer applications process the data in real or near real-time which makes the Kinesis Data Streams service most useful for building time-sensitive applications like real-time dashboards and anomaly detection.
Another common use of Kinesis Data Streams is the real-time aggregation of data followed by loading the aggregated data into a data warehouse or map-reduce cluster.
The data is stored in Kinesis Data Stream for 24 hours by default but it can be configured to up to 365 days.
Streams, Shards, and Records
When using Kinesis Data Streams, we first set up a data stream and then build producer applications that push data to the data stream and consumer applications that read and process the data from the data stream:
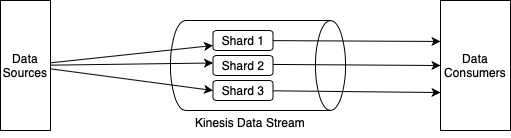
The Kinesis Data Stream is composed of multiple data carriers called shards, as we can see in this diagram. Each shard provides a fixed unit of capacity. The data capacity of a data stream is a function of the number of shards in the stream. The total capacity of the data stream is the sum of the capacities of all the shards it is composed of.
The data stored in the shard is called a record.
Each shard contains a sequence of data records. Each data record has a sequence number that is assigned by the Kinesis Data Stream.
Creating a Kinesis Data Stream
Let us first create our data stream where we can send streaming data from various data sources.
We can create a Kinesis data stream either by using the AWS Kinesis Data Streams Management Console, from the AWS Command Line Interface (CLI) or using the CreateStream operation of Kinesis Data Streams API from the AWS SDK.
We can also use AWS CloudFormation or AWS CDK to create a data stream as part of an infrastructure-as-code project.
Our code for creating a data stream with the Kinesis Data Streams API looks like this:
public class DataStreamResourceHelper {
public static void createDataStream() {
KinesisClient kinesisClient = getKinesisClient();
// Prepare Create stream request with stream name and stream mode
CreateStreamRequest createStreamRequest
= CreateStreamRequest
.builder()
.streamName(Constants.MY_DATA_STREAM)
.streamModeDetails(
StreamModeDetails
.builder()
.streamMode(StreamMode.ON_DEMAND)
.build())
.build();
// Create the data stream
CreateStreamResponse createStreamResponse
= kinesisClient.createStream(createStreamRequest);
...
...
}
private static KinesisClient getKinesisClient() {
AwsCredentialsProvider credentialsProvider =
ProfileCredentialsProvider
.create(Constants.AWS_PROFILE_NAME);
KinesisClient kinesisClient = KinesisClient
.builder()
.credentialsProvider(credentialsProvider)
.region(Region.US_EAST_1).build();
return kinesisClient;
}
}
In this code snippet, we are creating a Kinesis Data Stream with ON_DEMAND capacity mode. The capacity mode of ON_DEMAND is used for unpredictable workloads which scale the capacity of the data stream automatically in response to varying data traffic.
With the Kinesis Data Stream created, we will look at how to add data to this stream in the next sections.
Kinesis Data Stream Records
Before adding data, it is also important to understand the structure of data that is added to a Kinesis Data Stream.
Data is written to a Kinesis Data Stream as a record.
A record in a Kinesis data stream consists of:
- a sequence number,
- a partition key, and
- a data blob.
The maximum size of a data blob (the data payload before Base64-encoding) is 1 megabyte (MB).
A sequence number is a unique identifier for each record. The sequence number is assigned by the Kinesis Data Streams service when a producer application calls the PutRecord() or PutRecords() operation to add data to a Kinesis Data Stream.
The partition key is used to segregate and route records to different shards of a stream. We need to specify the partition key in the producer application while adding data to a Kinesis data stream.
For example, if we have a data stream with two shards: shard1 and shard2, we can write our producer application to use two partition keys: key1 and key2 so that all records with key1 are added to shard1 and all records with key2 are added to shard2.
Data Ingestion - Writing Data to Kinesis Data Streams
Applications that write data to Kinesis Data Streams are called “producers”. Producer applications can be custom-built in a supported programming language using AWS SDK or by using the Kinesis Producer Library (KPL).
We can also use Kinesis Agent which is a stand-alone application that we can run as an agent on Linux-based server environments such as web servers, log servers, and database servers.
Let us create a producer application in Java that will use the AWS SDK’s PutRecord() operation for adding a single record and the PutRecords() operation for adding multiple records to the Kinesis Data Stream.
We have created this producer application as a Maven project and added a Maven dependency in our pom.xml as shown below:
<dependencies>
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>kinesis</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>bom</artifactId>
<version>2.17.116</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
In the pom.xml, we have added the kinesis library as a dependency after adding bom for AWS SDK.
Here is the code for adding a single event to the Kinesis Data Stream that we created in the previous step:
public class EventSender {
private static final Logger logger = Logger
.getLogger(EventSender.class.getName());
public static void main(String[] args) {
sendEvent();
}
public static void sendEvent() {
KinesisClient kinesisClient = getKinesisClient();
// Set the partition key
String partitionKey = "partitionKey1";
// Create the data to be sent to Kinesis Data Stream in bytes
SdkBytes data = SdkBytes.fromByteBuffer(
ByteBuffer.wrap("Test data".getBytes()));
// Create the request for putRecord method
PutRecordRequest putRecordRequest
= PutRecordRequest
.builder()
.streamName(Constants.MY_DATA_STREAM)
.partitionKey(partitionKey)
.data(data)
.build();
// Call the method to write the record to Kinesis Data Stream
PutRecordResponse putRecordsResult
= kinesisClient.putRecord(putRecordRequest);
logger.info("Put Result" + putRecordsResult);
kinesisClient.close();
}
// Set up the Kinesis client by reading aws credentials
private static KinesisClient getKinesisClient() {
AwsCredentialsProvider credentialsProvider =
ProfileCredentialsProvider
.create(Constants.AWS_PROFILE_NAME);
KinesisClient kinesisClient = KinesisClient
.builder()
.credentialsProvider(credentialsProvider)
.region(Region.US_EAST_1).build();
return kinesisClient;
}
}
Here we are first creating the request object for the putRecord() method by specifying the name of the Kinesis Data Stream, partition key, and the data to be sent in bytes. Then we have invoked the putRecord() method on the kinesisClient to add a record to the stream.
Running this program gives the following output:
INFO: Put ResultPutRecordResponse(ShardId=shardId-000000000001, SequenceNumber=49626569155656830268862440193769593466823195675894743058)
We can see the shardId identifier of the shard where the record is added along with the sequence number of the record.
Let us next add multiple events to the Kinesis data stream by using the putRecords() method as shown below:
public class EventSender {
private static final Logger logger =
Logger.getLogger(EventSender.class.getName());
public static void main(String[] args) {
sendEvents();
}
public static void sendEvents() {
KinesisClient kinesisClient = getKinesisClient();
String partitionKey = "partitionKey1";
List<PutRecordsRequestEntry> putRecordsRequestEntryList
= new ArrayList<>();
// Create collection of 5 PutRecordsRequestEntry objects
// for adding to the Kinesis Data Stream
for (int i = 0; i < 5; i++) {
SdkBytes data = ...
PutRecordsRequestEntry putRecordsRequestEntry =
PutRecordsRequestEntry.builder()
.data(data)
.partitionKey(partitionKey)
.build();
putRecordsRequestEntryList.add(putRecordsRequestEntry);
}
// Create the request for putRecords method
PutRecordsRequest putRecordsRequest
= PutRecordsRequest
.builder()
.streamName(Constants.MY_DATA_STREAM)
.records(putRecordsRequestEntryList)
.build();
PutRecordsResponse putRecordsResult = kinesisClient
.putRecords(putRecordsRequest);
logger.info("Put records Result" + putRecordsResult);
kinesisClient.close();
}
// Set up the Kinesis client by reading aws credentials
private static KinesisClient getKinesisClient() {
...
...
}
}
Here we are using the following steps for adding a set of 5 records to the data stream:
-
Creating a collection of
PutRecordsRequestEntryobjects corresponding to each data record to be put in the data stream. In eachPutRecordsRequestEntryobject, we are specifying the partition key and the data payload in bytes. -
Creating the
PutRecordsRequestobject which we will pass as the input parameter to theputRecords()method by specifying the name of the data stream, and the collection of data records created in the previous step. -
Invoking the
putRecords()method to add the collection of5records to the data stream.
Running this program gives the following output:
ResultPutRecordsResponse(FailedRecordCount=0,
Records=[
PutRecordsResultEntry(SequenceNumber=49626569155656830268862440193770802392642928158972051474, ShardId=shardId-000000000001),
PutRecordsResultEntry(SequenceNumber=49626569155656830268862440193772011318462542788146757650, ShardId=shardId-000000000001),
PutRecordsResultEntry(SequenceNumber=49626569155656830268862440193773220244282157417321463826, ShardId=shardId-000000000001),
PutRecordsResultEntry(SequenceNumber=49626569155656830268862440193774429170101772046496170002, ShardId=shardId-000000000001),
PutRecordsResultEntry(SequenceNumber=49626569155656830268862440193775638095921386675670876178, ShardId=shardId-000000000001)])
In this output, we can see the same shardId for all the 5 records which got added to the stream which means they have all been put into the same shard with shardId: shardId-000000000001. This is because we have used the same value of partition key: partitionKey1 for all our records.
As mentioned before, other than the AWS SDK, we can use the Kinesis Producer Library (KPL) or the Kinesis agent for adding data to a Kinesis Data Stream:
-
Kinesis Producer Library (KPL): KPL is a library written in C++ for adding data into a Kinesis data stream. It runs as a child process to the main user process. So in case the child process stops due to an error when connecting or writing to a Kinesis Data Stream, the main process continues to run. Please refer to the documentation for guidance on developing producer applications using the Kinesis Producer Library.
-
Amazon Kinesis Agent: Kinesis Agent is a stand-alone application that we can run as an agent on Linux-based server environments such as web servers, log servers, and database servers. The agent continuously monitors a set of files and collects and sends new data to Kinesis Data Streams. Please refer to the official documentation for guidance on configuring Kinesis Agent in a Linux-based server environment.
Data Consumption - Reading Data from Kinesis Data Streams
With the data ingested in our data stream, let us get into creating a consumer application that can process the data from this data stream.
Earlier we had created a Kinesis Data Stream and added streaming data to it using the putRecord() and putRecords() operation of the Kinesis Data Streams API. We can also use the Kinesis Data Streams API from the AWS SDK for reading the streaming data from this Kinesis Data Stream as shown below:
public class EventConsumer {
public static void receiveEvents() {
KinesisClient kinesisClient = getKinesisClient();
String shardId = "shardId-000000000001";
// Prepare the shard iterator request with the stream name
// and identifier of the shard to which the record was written
GetShardIteratorRequest getShardIteratorRequest
= GetShardIteratorRequest
.builder()
.streamName(Constants.MY_DATA_STREAM)
.shardId(shardId)
.shardIteratorType(ShardIteratorType.TRIM_HORIZON.name())
.build();
GetShardIteratorResponse getShardIteratorResponse
= kinesisClient
.getShardIterator(getShardIteratorRequest);
// Get the shard iterator from the Shard Iterator Response
String shardIterator = getShardIteratorResponse.shardIterator();
while (shardIterator != null) {
// Prepare the get records request with the shardIterator
GetRecordsRequest getRecordsRequest
= GetRecordsRequest
.builder()
.shardIterator(shardIterator)
.limit(5)
.build();
// Read the records from the shard
GetRecordsResponse getRecordsResponse
= kinesisClient.getRecords(getRecordsRequest);
List<Record> records = getRecordsResponse.records();
logger.info("count " + records.size());
// log content of each record
records.forEach(record -> {
byte[] dataInBytes = record.data().asByteArray();
logger.info(new String(dataInBytes));
});
shardIterator = getRecordsResponse.nextShardIterator();
}
kinesisClient.close();
}
// set up the Kinesis Client
private static KinesisClient getKinesisClient() {
AwsCredentialsProvider credentialsProvider =
ProfileCredentialsProvider
.create(Constants.AWS_PROFILE_NAME);
KinesisClient kinesisClient = KinesisClient
.builder()
.credentialsProvider(credentialsProvider)
.region(Region.US_EAST_1).build();
return kinesisClient;
}
}
Here we are invoking the getRecords() method on the Kinesis client to read the ingested records from the Kinesis Data Stream. We have provided a shard iterator using the ShardIterator parameter in the request.
The shard iterator specifies the position in the shard from which we want to start reading the data records sequentially. We will get an empty list if there are no records available in the portion of the shard that the iterator is pointing to so we have used a while loop to make multiple calls to get to the portion of the shard that contains records.
Consumers of Kinesis Data Streams
Kinesis Data Streams API which we used till now is a low-level method of reading streaming data. We have to take care of polling the stream, checkpointing processed records, running multiple instances, etc when we are using Kinesis Data Streams API for performing operations on a data stream.
So in most practical situations, we use the following methods for creating consumer applications for reading data from the stream:
-
AWS Lambda: We can use an AWS Lambda function to process records in an Amazon Kinesis data stream. AWS Lambda integrates natively with Amazon Kinesis Data Stream as a consumer to process data ingested through a data stream by taking care of the polling, checkpointing, and error handling functions. Please refer to the AWS Lambda documentation for the steps to configure a Lambda function as a consumer to a Kinesis Data Stream.
-
Kinesis Client Library (KCL): We can build a consumer application for Amazon Kinesis Data Streams using the Kinesis Client Library (KCL). The KCL is different from the Kinesis Data Streams API used earlier. It provides a layer of abstraction around the low-level tasks like connecting to the stream, reading the record from the stream, checkpointing processed records, and reacting to resharding. For information on using KCL, check the documentation for developing KCL consumers.
-
Kinesis Data Firehose: Kinesis Data Firehose is a fully managed service for delivering real-time streaming data to destinations such as Amazon S3, Amazon Redshift, Amazon OpenSearch Service, and Splunk. We can set up the Kinesis Data Stream as a source of streaming data to a Kinesis Firehose delivery stream for delivering after optionally transforming the data to a configured destination. We will explain this mechanism further in the section on Kinesis Data Firehose.
-
Kinesis Data Analytics: Kinesis Data Analytics is another fully managed service from the Kinesis family for processing and analyzing streaming data with helpful programming constructs like windowing, sorting, filtering, etc. We can set up the Kinesis Data Stream as a source of streaming data to a Kinesis Data Analytics application which we will explain in the section on Kinesis Data Analytics.
Throughput Limits - Shared vs. Enhanced Fan-Out Consumers
It is important to understand the throughput limits of Kinesis Data Stream for designing and operating a highly reliable data streaming system and ensuring predictable performance.
As explained before, the Kinesis Data Stream is composed of multiple data carriers called shards which contain a sequence of data records. Each shard provides a fixed unit of capacity thereby serving as a base throughput unit of a Kinesis data stream. The data capacity of a data stream is a function of the number of shards in the stream.
A shard supports 1 MB/second and 1,000 records per second for write throughput and 2 MB/second for read throughput.
When we have multiple consumers reading from a shard, this read throughput is shared between them. These types of consumers are called Shared fan-out consumers.
If we want dedicated throughput for consumers, we can define them as Enhanced fan-out consumers.
Enhanced fan-out is an optional feature for Kinesis Data Streams consumers that provides dedicated 2 MB/second throughput between consumers and shards. This helps to scale the number of consumers reading from a data stream in parallel while maintaining high performance.
These consumers do not have to share this throughput with other consumers that are receiving data from the stream. The data records from the stream are also pushed to these consumers that use enhanced fan-out.
The producer and consumer applications will receive throttling errors when writes and reads exceed the shard limits, which are handled through retries.
Kinesis Data Firehose
Kinesis Data Firehose is a fully managed service that is used to deliver streaming data to a destination in near real-time.
One or more data producers send their streaming data into a kind of “pipe” called a delivery stream which optionally applies some transformation to the data before delivering it to a destination. An example of a data producer for a Kinesis Data Firehose is a web server that sends log data to a delivery stream.
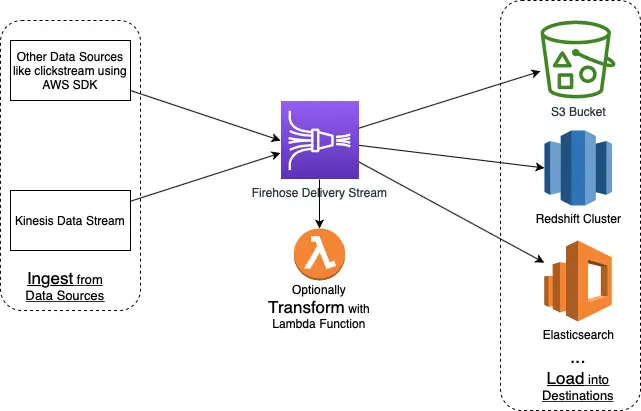
The incoming streaming data is buffered in the delivery stream till it reaches a particular size or exceeds a certain time interval before it is delivered to the destination. Due to this reason, Kinesis Data Firehose is not intended for real-time delivery. It groups incoming streaming data, optionally compressing and/or transforming them with AWS Lambda functions, and then puts the data into a sink which is usually an AWS service like S3, Redshift, or Elasticsearch.
We can configure the delivery stream to read streaming data from a Kinesis Data Stream and deliver it to a destination.
We also need to do very little programming when using Kinesis Data Firehose. This is unlike Kinesis Data Streams where we write custom applications for producers and consumers of a data stream.
Creating a Kinesis Firehose Delivery Stream
Let us take a closer look at the Kinesis Data Firehose service by creating a Firehose delivery stream. We can create a Firehose delivery stream using the AWS management console, AWS SDK, or infrastructure as a service like AWS CloudFormation and AWS CDK.
For our example, let us use the AWS management console for creating the delivery stream as shown below:
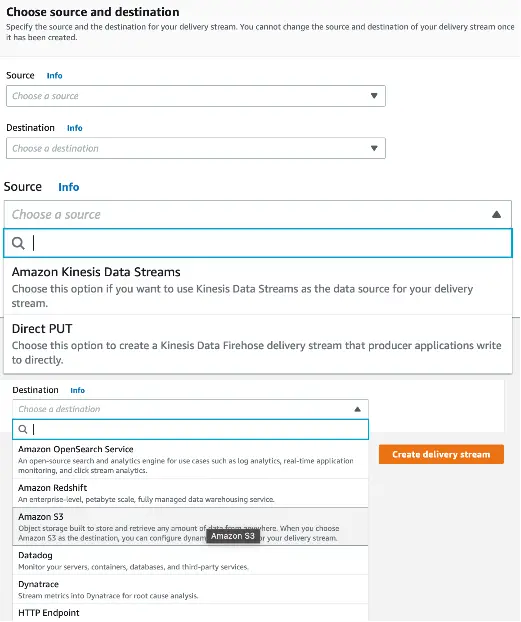
We configure a delivery stream in Firehose with a source and a destination.
The source of a Kinesis Data Firehose delivery stream can be :
- A Kinesis Data Stream
Direct PUTmeans an application producer can send data to the delivery stream using a directPUToperation.
Here we have chosen the source as Direct PUT.
Similarly, the delivery stream can send data to the following destinations:
- Amazon Simple Storage Service (Amazon S3),
- Amazon Redshift
- Amazon OpenSearch Service
- Splunk, and
- Any custom HTTP endpoint or HTTP endpoints owned by supported third-party service providers like Datadog, Dynatrace, LogicMonitor, MongoDB, New Relic, and Sumo Logic.
For our example, we have chosen our destination as S3 and configured an S3 bucket that will receive the streaming data delivered by our Firehose delivery stream.
Apart from this we also need to assign an IAM service role to the Kinesis Firehose service with an access policy that allows it to write to the S3 bucket.
The delivery stream which we created using this configuration looks like this:
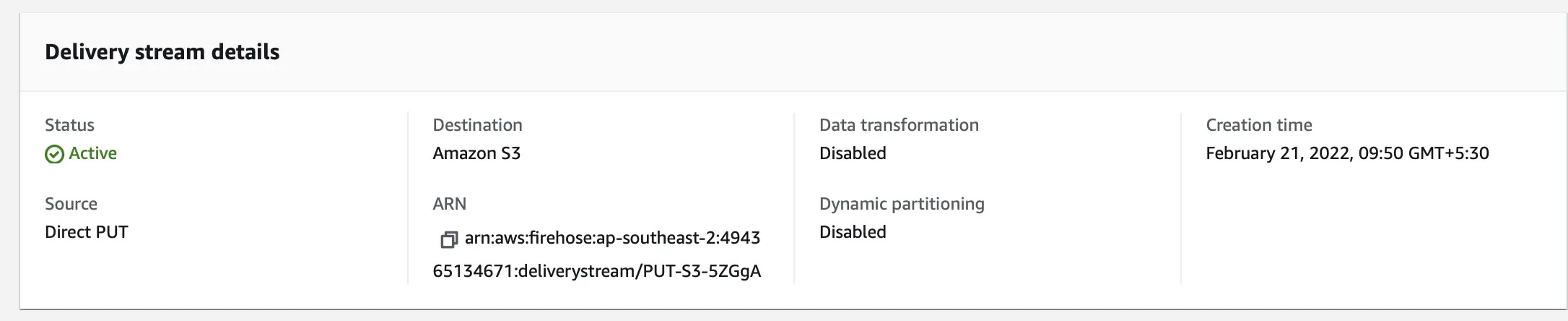
In this screenshot, we can observe a few more properties of the delivery stream like Data transformation and Dynamic partitioning which we will understand in the subsequent sections. We can also see the status of the delivery stream as Active which means it can receive streaming data. The initial status of the delivery stream is CREATING.
We are now ready to send streaming data to our Firehose delivery stream which will deliver this data to the configured destination: S3 bucket.
Sending Data to a Kinesis Firehose Delivery Stream
We can send data to a Kinesis Data Firehose delivery stream from different types of sources:
-
Kinesis Data Stream: We can configure Kinesis Data Streams to send data records to a Kinesis Data Firehose delivery stream by setting the Kinesis Data Stream as the
Sourcewhen we are creating the delivery stream. -
Kinesis Firehose Agent: Kinesis Firehose Agent is a standalone Java application that collects log data from a server and sends them to Kinesis Data Firehose. We can install this agent in Linux-based servers and configure it by specifying the files to monitor along with the delivery stream to which the log data is to be sent. More details about configuring a Kinesis Firehose Agent can be found in the official documentation.
-
Kinesis Data Firehose API: Kinesis Data Firehose API from the AWS SDK offers two operations for sending data to the Firehose delivery stream:
PutRecord()andPutRecordBatch(). ThePutRecord()operation sends one data record while thePutRecordBatch()operation can send multiple data records to the delivery stream in a single invocation. We can use these operations only if the delivery stream is created with theDIRECT PUToption as theSource. -
Amazon CloudWatch Logs: CloudWatch Logs are used to centrally store and monitor logs from all our systems, applications, and dependent AWS services. We can create a CloudWatch Logs subscription that will send log events to Kinesis Data Firehose. Please refer to the documentation for steps to configure Subscription Filters with Amazon Kinesis Firehose.
-
CloudWatch Events: We can configure Amazon CloudWatch to send events to a Kinesis Data Firehose delivery stream by creating a CloudWatch Events rule with the Firehose delivery stream as a target.
-
AWS IoT as the data source: We can configure AWS IoT to send data to a Kinesis Data Firehose delivery stream by adding a rule action for an AWS IoT rule.
For our example, let us use the Kinesis Data Firehose API to send a data record to the Firehose delivery stream. A very simplified code snippet for sending a single record to a Kinesis Firehose delivery stream looks like this:
public class FirehoseEventSender {
private final static Logger logger =
Logger.getLogger(FirehoseEventSender.class.getName());
public static void main(String[] args) {
new FirehoseEventSender().sendEvent();
}
public void sendEvent() {
String deliveryStreamName = "PUT-S3-5ZGgA";
String data = "Test data" + "\n";
// Create a record for sending to Firehose Delivery Stream
Record record = Record
.builder()
.data(SdkBytes
.fromByteArray(data.getBytes()))
.build();
// Prepare the request for putRecord operation
PutRecordRequest putRecordRequest =
PutRecordRequest
.builder()
.deliveryStreamName(deliveryStreamName)
.record(record)
.build();
FirehoseClient firehoseClient = getFirehoseClient();
// Put record into the DeliveryStream
PutRecordResponse putRecordResponse =
firehoseClient.putRecord(putRecordRequest);
logger.info("record ID:: " + putRecordResponse.recordId());
firehoseClient.close();
}
// Create the FirehoseClient with the AWS credentials
private static FirehoseClient getFirehoseClient() {
AwsCredentialsProvider credentialsProvider =
ProfileCredentialsProvider
.create(Constants.AWS_PROFILE_NAME);
FirehoseClient kinesisClient = FirehoseClient
.builder()
.credentialsProvider(credentialsProvider)
.region(Constants.AWS_REGION).build();
return kinesisClient;
}
}
Here we are calling the putRecord() method of the Kinesis Data Firehose API for adding a single record to the delivery stream. The putRecord() method takes an object of type PutRecordRequest as input parameter. We have set the name of the delivery stream along with the contents of the data when creating the input parameter object before invoking the putRecord() method.
Data Transformation in a Firehose Delivery Stream
We can configure the Kinesis Data Firehose delivery stream to transform and convert streaming data received from the data source before delivering the transformed data to destinations:
Transforming Incoming Data: We can invoke a Lambda function to transform the data received in the delivery stream. Some ready-to-use blueprints are offered by AWS which we can adapt according to our data format.
Converting the Format of the Incoming Data Records: We can convert the format of our input data from JSON to Apache Parquet or Apache ORC before storing the data in Amazon S3. Parquet and ORC are columnar data formats that save space and enable faster queries compared to row-oriented formats like JSON. If we want to convert an input format other than JSON, such as comma-separated values (CSV) or structured text, we can use a Lambda function to transform it to JSON.
The below figure shows the data transformation and record format conversion options enabled in the AWS management console:
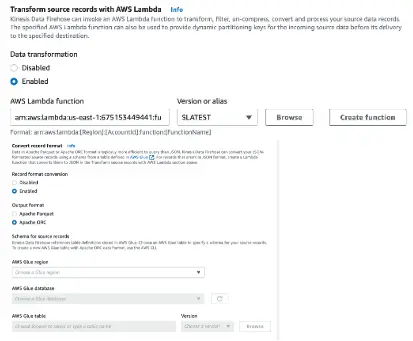
Here is the snippet of a Lambda function for transforming the streaming data record created using a Lambda blueprint for Kinesis Data Firehose Processing:
console.log('Loading function');
const validateRecord = (recordElement)=>{
// record is considered valid if contains status field
return recordElement.includes("status")
}
exports.handler = async (event, context) => {
/* Process the list of records and transform them */
const output = event.records.map((record)=>{
const decodedData = Buffer.from(record.data, "base64").toString("utf-8")
let isValidRecord = validateRecord(decodedData)
if(isValidRecord){
let parsedRecord = JSON.parse(decodedData)
// read fields from parsed JSON for some more processing
const outputRecord = `status::${parsedRecord.status}`
return {
recordId: record.recordId,
result: 'Ok',
// payload is encoded back to base64 before returning the result
data: Buffer.from(outputRecord, "utf-8").toString("base64")
}
}else{
return {
recordId: record.recordId,
result: 'dropped',
data: record.data // payload is kept intact,
}
}
})
};
This lambda function is written in Node.js. It validates the record by looking for a status field. If it finds the record as valid, it parses the JSON record to extract the status field and prepares the response before passing the processed record back into the stream for delivery.
Data Delivery Format of a Firehose Delivery Stream
After our delivery stream receives the streaming data, it is automatically delivered to the configured destination. Each destination type supported by Kinesis Data Firehose has specific configurations for data delivery.
For data delivery to S3, Kinesis Data Firehose concatenates multiple incoming records based on the buffering configuration of our delivery stream. It then delivers the records to the S3 bucket as an S3 object. We can also add a record separator at the end of each record before sending them to Kinesis Data Firehose. This will help us to divide the delivered Amazon S3 object into individual records.
Kinesis Data Firehose adds a UTC time prefix in the format YYYY/MM/dd/HH before writing objects to an S3 bucket. This prefix creates a logical hierarchy in the bucket, where each / creates a level in the hierarchy.
The path of our S3 object created as a result of delivery of our streaming data with the Direct PUT operation results in a hierarchy of the form s3://<S3 bucket name>/2022/02/22/03/ in the S3 bucket configured as a destination to the Firehose delivery stream.
The data delivery format of other destinations can be found in the official documentation of Kinesis Data Firehose.
Kinesis Data Analytics
Kinesis Data Analytics helps us to transform and analyze streaming data. It does this by providing a fully managed environment for running Flink applications.
Apache Flink is a Big Data processing framework for processing a large amount of data efficiently. It has helpful constructs like windowing, filtering, aggregations, mapping, etc for performing operations on streaming data.
The results of analyzing streaming data can be used in various use cases like performing time-series analytics, feeding real-time dashboards, and creating real-time metrics.
Kinesis Data Analytics sets up the resources to run Flink applications and scales automatically to handle any volume of incoming data.
The Difference Between Kinesis Data Streams and Kinesis Data Anbalytics
It is important to note the difference with Kinesis Data Stream where we can also write consumer applications with custom code for performing any processing on the streaming data. But those applications are usually run on server instances like EC2 in an infrastructure provisioned and managed by us.
Kinesis Data Analytics in contrast provides an automatically provisioned environment for running applications built using the Flink framework which scales automatically to handle any volume of incoming data.
Consumer applications of Kinesis Data Streams usually write the records to a destination like an S3 bucket or a DynamoDB table after some processing. Kinesis Data Analytics applications perform queries like aggregations, filtering, etc. by applying different windows on streaming data to identify trends and patterns for real-time alerts and feeds for dashboards.
Kinesis Data Analytics also supports applications built using Java with the open-source Apache Beam libraries and our own custom code.
Structure of a Flink Application
A basic structure of a Flink application is shown below:
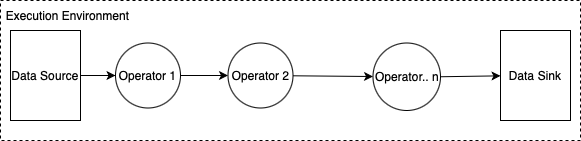
In this diagram, we can observe the following components of the Flink application:
- Execution Environment: The execution environment of a Flink application is defined in the application main class and creates the data pipeline. The data pipeline contains the business logic and is composed of one or more operators chained together.
- Data Source: The application consumes data by using a source. A source connector reads data from a Kinesis data stream, an Amazon S3 bucket, etc.
- Processing Operators: The application processes data by using one or more operators. These processing operators apply transformations to the input data that comes from the data sources. After the transformation, the application forwards the transformed data to the data sinks. Please check out the Flink documentation to see the complete list of DataStream API Operators with code snippets.
- Data Sink: The application produces data to external sources by using sinks. A sink connector writes data to a Kinesis data stream, a Kinesis Data Firehose delivery stream, an Amazon S3 bucket, etc.
A few basic data sources and sinks are built into Flink and are always available. Examples of predefined data sources are reading from files, and sockets, and ingesting data from collections and iterators. Similarly, examples of predefined data sink include writing to files, to stdout and stderr, and sockets.
Creating a Flink Application
Let us first create a Flink application which we will run using the Kinesis Data Analytics service. We can create a Flink application in Java, Scala or Python. We will create the application for our example as a Maven project in Java language and set up the following dependencies:
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.14.3</version>
</dependency>
<dependency>
<groupId>software.amazon.kinesis</groupId>
<artifactId>amazon-kinesis-connector-flink</artifactId>
<version>2.3.0</version>
</dependency>
...
</dependencies>
The dependency: flink-streaming-java_2.11 contains the core API of Flink. We have added the flink-clients_2.11 dependency for running the Flink application locally. For connecting to Kinesis we are using the dependency: amazon-kinesis-connector-flink.
Let us use a stream of access logs from an Apache HTTP server as our streaming data that we will use for processing by our Flink application. We will first test our application using a text file as a pre-defined source and stdout as a pre-defined sink.
The code for processing this stream of access logs is shown below:
public class ErrorCounter {
private final static Logger logger =
Logger.getLogger(ErrorCounter.class.getName());
public static void main(String[] args) throws Exception {
// set up the streaming execution environment
final StreamExecutionEnvironment env =
StreamExecutionEnvironment
.getExecutionEnvironment();
// Create the source of streaming data
DataStream<String> inputStream = createSource(env);
// convert string to LogRecord event objects
DataStream<LogRecord> logRecords = mapStringToLogRecord(inputStream);
// Filter out error records (with status not equal to 200)
DataStream<LogRecord> errorRecords = filterErrorRecords(logRecords);
// Create keyed stream with IP as key
DataStream<LogRecord> keyedStream = assignIPasKey(errorRecords);
// convert LogRecord to string to objects
DataStream<String> keyedStreamAsText = mapLogRecordToString(keyedStream);
// Create sink
createSink(env, errorRecords);
// Execute the job
env.execute("Error alerts");
}
// convert LogRecord to string to objects using the Flink's flatMap operator
private static DataStream<String> mapLogRecordToString(
DataStream<LogRecord> keyedStream) {
DataStream<String> keyedStreamAsText
= keyedStream.flatMap(new FlatMapFunction<LogRecord, String>() {
@Override
public void flatMap(
LogRecord value,
Collector<String> out) throws Exception {
out.collect(value.getUrl()+"::" + value.getHttpStatus());
}
});
return keyedStreamAsText;
}
// Create keyed stream with IP as key using Flink's keyBy operator
private static DataStream<LogRecord> assignIPasKey(
DataStream<LogRecord> errorRecords) {
DataStream<LogRecord> keyedStream =
errorRecords.keyBy(value -> value.getIp());
return keyedStream;
}
// Filter out error records (with status not equal to 200)
// using Flink's filter operator
private static DataStream<LogRecord> filterErrorRecords(
DataStream<LogRecord> logRecords) {
DataStream<LogRecord> errorRecords =
logRecords.filter(new FilterFunction<LogRecord>() {
@Override
public boolean filter(LogRecord value) throws Exception {
boolean matched = !value.getHttpStatus().equalsIgnoreCase("200");
return matched;
}
});
return errorRecords;
}
// convert string to LogRecord event objects using Flink's flatMap operator
private static DataStream<LogRecord> mapStringToLogRecord(
DataStream<String> inputStream) {
DataStream<LogRecord> logRecords =
inputStream.flatMap(new FlatMapFunction<String, LogRecord>() {
@Override
public void flatMap(
String value,
Collector<LogRecord> out) throws Exception {
String[] parts = value.split("\\s+");
LogRecord record = new LogRecord();
record.setIp(parts[0]);
record.setHttpStatus(parts[8]);
record.setUrl(parts[6]);
out.collect(record);
}
});
return logRecords;
}
// Set up the text file as a source
private static DataStream<String> createSource(
final StreamExecutionEnvironment env) {
return env.readTextFile(
"<File Path>/apache_access_log");
}
// Set up stdout as the sink
private static void createSink(
final StreamExecutionEnvironment env,
DataStream<LogRecord> input) {
input.print();
}
}
We have used the DataStream API of Flink in this code example for processing the streams of access logs contained in the text file used as a source. Here we are first creating the execution environment using the StreamExecutionEnvironment class.
Next, we are creating the source for the streaming data. We have used a text file containing the log records from an Apache HTTP server as a source here. Some sample log records from the text file are shown here:
83.149.9.216 .. "GET /.../-search.png HTTP/1.1" 200 ..
83.149.9.216 .. "GET /.../-dashboard3.png HTTP/1.1" 200
83.149.9.216 .. "GET /.../highlight.js HTTP/1.1" 403 ..
...
...
After this, we have attached a chain of Flink operators to the source of the streaming data. Our sample code uses operators chained together in the below sequence:
- Flatmap: We are using the
Flatmapoperator to transform the String element to a POJO of typeLogRecord. FlatMap functions take elements and transform them, into zero, one, or more elements. - Filter: We have applied the
Filteroperator to select only the error records with HTTP status not equal to200. - KeyBy: With the
KeyByoperator we partition the records by IP address for parallel processing. - Flatmap: We are once again using another
Flatmapoperator to transform the POJO of typeLogRecordto aStringelement.
The result of the last operator is connected to a predefined sink: stdout.
Here is the output after running this application:
6> /doc/index.html?org/elasticsearch/action/search/SearchResponse.html::404
4> /presentations/logstash-monitorama-2013/css/fonts/Roboto-Bold.ttf::404
4> /presentations/logstash-monitorama-2013/images/frontend-response-codes.png::310
Configuring a Kinesis Data Stream as a Source and a Sink
After testing our data pipeline we will modify the data source in our code to connect to a Kinesis Data Stream which will ingest the streaming data which we want to process. For our example, it will be access logs from an Apache HTTP server ingested in a Kinesis Data Stream using an architecture as shown in this diagram:
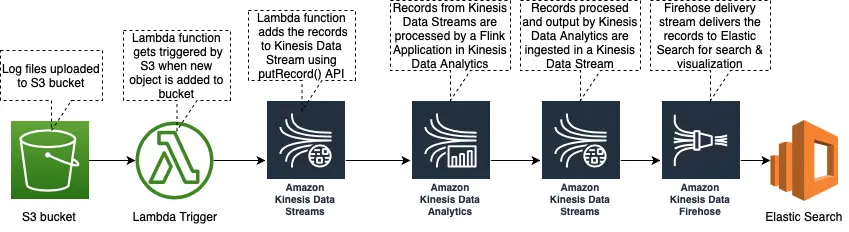
In this architecture, the access log files from the HTTP server will be uploaded to an S3 bucket. A lambda trigger attached to the S3 bucket will read the records from the file and add them to a Kinesis Data Stream using the putRecords() operation.
The source and the sink connected to Kinesis Data Stream looks like this:
public class ErrorCounter {
private final static Logger logger =
Logger.getLogger(ErrorCounter.class.getName());
public static void main(String[] args) throws Exception {
// set up the streaming execution environment
final StreamExecutionEnvironment env =
StreamExecutionEnvironment
.getExecutionEnvironment();
DataStream<String> inputStream = createSource(env);
...
...
...
DataStream<String> keyedStream = ...
keyedStream.addSink(createSink());
}
// Create Kinesis Data Stream as a source
private static DataStream<String> createSource(
final StreamExecutionEnvironment env) {
Properties inputProperties = new Properties();
inputProperties.setProperty(
ConsumerConfigConstants.AWS_REGION,
Constants.AWS_REGION.toString());
inputProperties.setProperty(
ConsumerConfigConstants.STREAM_INITIAL_POSITION,
"LATEST");
String inputStreamName = "in-app-log-stream";
return env.addSource(
new FlinkKinesisConsumer<>(
inputStreamName,
new SimpleStringSchema(),
inputProperties));
}
// Create Kinesis Data Stream as a sink
private static FlinkKinesisProducer<String> createSink() {
Properties outputProperties = new Properties();
outputProperties.setProperty(
ConsumerConfigConstants.AWS_REGION,
Constants.AWS_REGION.toString());
FlinkKinesisProducer<String> sink =
new FlinkKinesisProducer<>(
new SimpleStringSchema(), outputProperties);
String outputStreamName = "log_data_stream";
sink.setDefaultStream(outputStreamName);
sink.setDefaultPartition("0");
return sink;
}
}
Here we have added a Kinesis Data Stream of name in-app-log-stream as the source and another Kinesis Data Stream of name log_data_stream as the sink.
We can also configure destinations where you want Kinesis Data Analytics to send the results.
Kinesis Data Analytics also supports Kinesis Data Firehose and AWS Lambda as destinations. Kinesis Data Firehose can be configured to automatically send the data to destinations like S3, Redshift, OpenSearch, and Splunk.
Next, we need to compile and package this code for deploying to the Kinesis Data Analytics service. We will see this in the next section.
Deploying the Flink Application to Kinesis Data Analytics
Kinesis Data Analytics runs Flink applications by creating a job. It looks for a compiled source in an S3 bucket. Since our Flink application is in a Maven project, we will compile and package our application using Maven as shown below:
mvn package -Dflink.version=1.13.2
Running this command will create a fat “uber” jar with all the dependencies. We will upload this jar file to an S3 bucket where Kinesis Data Analytics will look for the application code.
We will next create an application in Kinesis Data Analytics using the AWS management console as shown below:
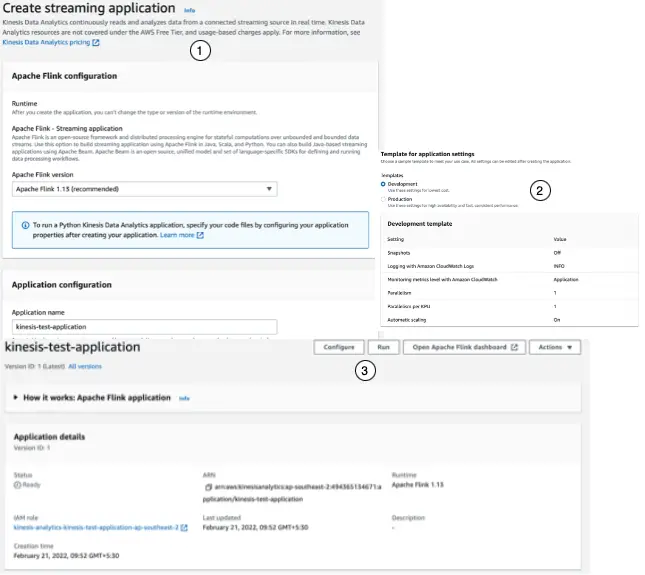
This application is the Kinesis Data Analytics entity that we work with for querying and operating on our streaming data.
We configure three primary components in an application:
- Input: In the input configuration, we map the streaming source to an in-application data stream. Data flows from one or more data sources into the in-application data stream. We have configured a Kinesis Data Stream as a data source.
- Application code: Location of an S3 bucket containing the compiled Flink application that reads from an in-application data stream associated with a streaming source and writes to an in-application data stream associated with output.
- Output: one or more in-application streams to store intermediate results. We can then optionally configure an application output to persist data from specific in-application streams to an external destination.
Our application’s dependent resources like CloudWatch Log streams and IAM service roles also get created in this step.
After the application is created, we will configure the application with the location of the S3 bucket where we had uploaded the compiled code of the Flink application as an “uber” jar earlier.
Running the Kinesis Data Analytics Application by Creating a Job
We can run our application by choosing Run on our application’s page in the AWS console. When we run our Kinesis Data Analytics application, the Kinesis Data Analytics service creates an Apache Flink job.
The execution of the job, and the resources it uses, are managed by a Job Manager. The Job Manager separates the execution of the application into tasks. Each task is managed by a Task Manager. We examine the performance of each Task Manager, or the Job Manager as a whole to monitor the performance of our application.
Creating Flink Application Interactively with Notebooks
The Flink application we built earlier was authored separately in a Java IDE (Eclipse) and then packaged and deployed in Kinesis Data Analytics by uploading the compiled artifact (jar file) to an S3 bucket.
Instead of using an IDE like Eclipse, we can use notebooks which are more widely used for data science tasks, for authoring Flink applications. A notebook is a web-based interactive development environment where data scientists write and execute code and visualize results.
Studio notebooks provided by Kinesis Data Streams use notebooks powered by Apache Zeppelin and use Apache Flink as the stream processing engine.
We can create a Studio notebooks in the AWS Management Console as shown below:
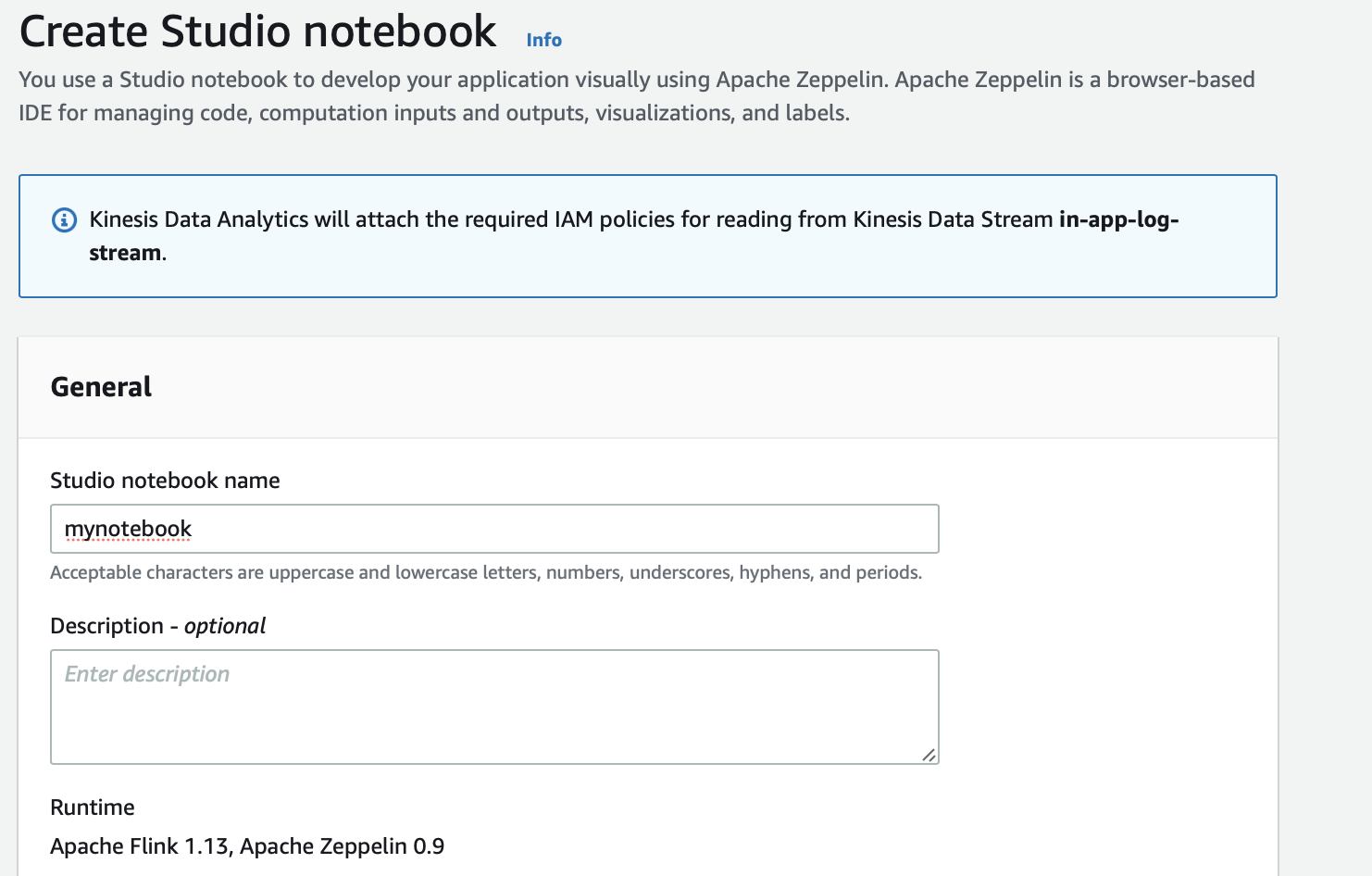
After we start the notebook, we can open it in Apache Zeppelin for writing code in SQL, Python, or Scala for developing applications using the notebook interface for Kinesis Data Streams, Amazon MSK, and S3 using built-in integrations, and various other streaming data sources with custom connectors.
Using Studio notebooks, we model queries on streaming data using the Apache Flink Table API and SQL in SQL, Python, Scala, or DataStream API in Scala. After that, we promote the Studio notebook to a continuously-running, non-interactive, Kinesis Data Analytics stream-processing application.
Please refer to the official documentation for details about using Studio notebook.
Kinesis Video Streams
Kinesis Video Streams is a fully managed service that we can use to :
- connect and stream video, audio, and other time-encoded data from various capturing devices using an infrastructure provisioned dynamically in the AWS Cloud
- securely and durably store media data for a default retention period of
1day and a maximum of10years. - build applications that operate on live data streams by consuming the ingested data frame-by-frame, in real-time for low-latency processing.
- create batch or ad hoc applications that operate on durably persisted data without strict latency requirements.
Key Concepts: Producer, Consumer, and Kinesis Video Stream
The Kinesis Video Streams service is built around the concepts of a producer sending the streaming data to a stream and a consumer application reading that data from the stream.
-
Producer: Any source that puts data into a Kinesis video stream. A producer can be any video-generating device, such as a security camera, a body-worn camera, a smartphone camera, or a dashboard camera. A producer can also send non-video data, such as audio feeds, images, or RADAR data.
-
Kinesis Video Stream: A resource that transports live video data, optionally stores it, and makes the data available for consumption both in real-time and on a batch or ad hoc basis.
-
Consumer: A consumer is an application that reads data like fragments and frames from a Kinesis Video Stream for viewing, processing, or analysis.
Creating a Kinesis Video Stream
Let us first create a Kinesis Video Stream using the AWS admin console:
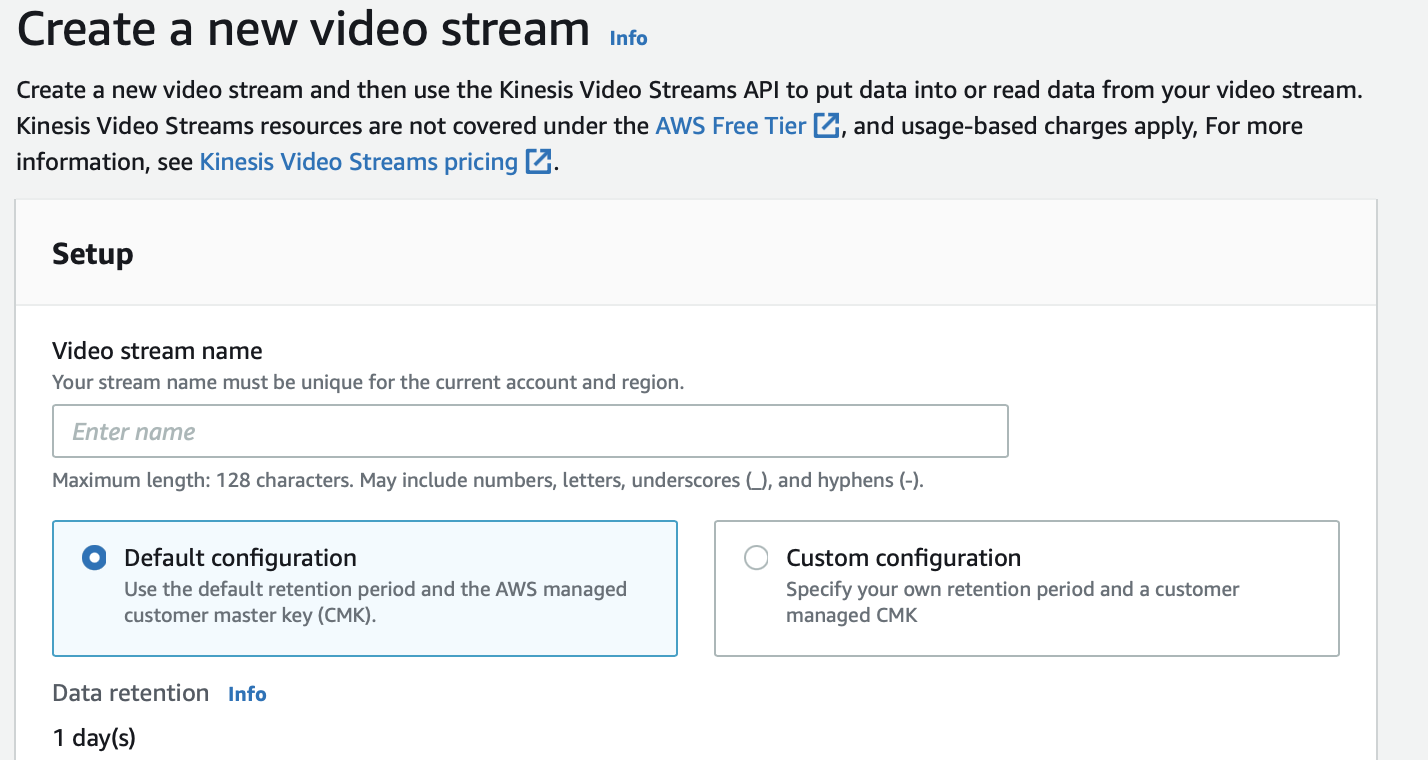

Here we have created a new video stream with a default configuration. We can then use the Kinesis Video Streams API to put data into or read data from this video stream.
Sending Media Data to a Kinesis Video Stream
Next, we need to configure a producer for putting data into this Kinesis Video Stream. The producer uses an application that extracts the video data in the form of frames from the media source and uploads it to the Kinesis Video Stream.
The producer uses a Kinesis Video Streams Producer SDK to extract the video data in the form of frames from the media source and sends it to the Kinesis Video Stream.
Kinesis Video Streams Producer SDK is used to build an on-device application that securely connects to a video stream, and reliably publishes video and other media data to Kinesis Video Stream.
It takes care of all the underlying tasks required to package the frames and fragments generated by the device’s media pipeline. The SDK also handles stream creation, token rotation for secure and uninterrupted streaming, processing acknowledgments returned by Kinesis Video Streams, and other tasks.
Please refer to the documentation for details about using the Producer SDK.
Consuming Media Data from a Kinesis Video Stream
We can consume media data by either viewing it in the AWS Kinesis Video Stream console or by creating an application that reads media data from a Kinesis Video Stream.
The Kinesis Video Stream Parser Library is a set of tools that can be used in Java applications to consume the MKV data from a Kinesis Video Stream.
Please refer to the documentation for details about configuring the Parser library.
Conclusion
Here is a list of the major points for a quick reference:
- Streaming data is a pattern of data being generated continuously (in a stream) by multiple data sources which typically send the data records simultaneously. Due to its continuous nature, streaming data is also called unbounded data as opposed to bounded data handled by batch processing systems.
- Amazon Kinesis is a family of managed services for collecting and processing streaming data in real-time.
- Amazon Kinesis includes the following services each focussing on different stages of handling streaming data :
- Kinesis Data Stream for ingestion and storage of streaming data
- Kinesis Firehose for delivery of streaming data
- Kinesis Analytics for running analysis programs over the ingested data for deriving analytical insights
- Kinesis Video Streams for ingestion, storage, and streaming of media data
- The Kinesis Data Streams service is used to collect and process streaming data in real-time.
- The Kinesis Data Stream is composed of multiple data carriers called shards. Each shard provides a fixed unit of capacity.
- Kinesis Data Firehose is a fully managed service that is used to deliver streaming data to a destination in near real-time. The incoming streaming data is buffered in the delivery stream till it reaches a particular size or exceeds a certain time interval before it is delivered to the destination. Due to this reason, Kinesis Data Firehose is not intended for real-time delivery.
- Kinesis Data Analytics is used to analyze streaming data in real-time. It provides a fully managed service for running Apache Flink applications. Apache Flink is a Big Data processing framework for building applications that can process a large amount of data efficiently. Kinesis Data Analytics sets up the resources to run Flink applications and scales automatically to handle any volume of incoming data.
- Kinesis Video Streams is a fully managed AWS service that we can use to ingest streaming video, audio, and other time-encoded data from various media capturing devices using an infrastructure provisioned dynamically in the AWS Cloud.
You can refer to all the source code used in the article on Github.



